El modelo relacional de datos supuso un gran avance con respecto a los modelos anteriores. Este modelo está basado en el concepto de relación. Una relación es un conjunto de n-tuplas. Una tupla, al contrario que un segmento, puede representar tanto entidades como interrelaciones13 N:M. Los lenguajes matemáticos sobre los que se asienta el modelo relacional, el álgebra y el cálculo relacionales, aportan un sistema de acceso y consultas orientado al conjunto. La repercusión del modelo en los DBMSs comerciales actuales ha sido enorme, estando hoy en día la gran mayoría de los gestores de bases de datos basados en mayor o menor medida en el modelo relacional.
El concepto de modelo de datos en sí surgió al mismo tiempo que el modelo relacional de datos fuera propuesto por su creador, Ted Codd, después de que los modelos jerárquico y de red estuvieran en uso. Posteriormente, estos dos modelos fueron definidos independientemente de los lenguajes y sistemas usados para implementarlos. Con anterioridad no eran más que colecciones de estructuras de datos y lenguajes sin una teoría subyacente definida. En cuanto al modelo relacional, no se puede decir que sea en sí un modelo semántico de datos. Su enorme éxito no se debe a que permite de forma implícita operaciones conceptualmente abstractas sobre los datos, sino a los altos niveles de fiabilidad e integridad que aporta en el manejo de grandes cantidades de datos.
Desde su comienzo en 1970 y durante mucho tiempo después, los sistemas gestores de bases de datos relacionales (RDBMS : Relational Database Management System) estuvieron restringidos al ámbito de los mainframes y mini-ordenadores. Con la irrupción masiva en el mercado de los micro-ordenadores, aparecieron algunas implementaciones de RDBMSs que intentaban emular las propiedades de los grandes sistemas, aunque no contaban con la mayor parte de las características necesarias para ser denominados "relacionales", especialmente en lo que se refiere al cumplimiento de las reglas de integridad relacional.
Hoy en día contamos con RDBMSs para micro-ordenadores que sí pueden ser considerados plenamente relacionales y que, si bien no llegan alcanzar las prestaciones de los grandes sistemas en cuanto a velocidad de ejecución, seguridad, integridad de datos, recuperación y estabilidad, no tienen nada que envidiar a éstos cualitativamente, y sus deficiencias se deben sobre todo al tipo de máquina en el que funcionan y a los sistemas operativos que estas máquinas utilizan.
Lo que realmente marca la diferencia entre los sistemas relacionales y los sistemas anteriores es el hecho de que su creador, Ted Codd, basó expresamente su funcionamiento sobre un modelo matemático muy específico: el álgebra relacional y el cálculo relacional, así como la progresiva adopción, por parte de su creador y algunos colaboradores, de un número de Reglas de Integridad Relacional y de Formas Normales.
La definición formal y exhaustiva más actualizada del modelo se encuentra en (Codd 1990). Además existen un buen número de obras que tratan el modelo desde diversas perspectivas; entre éstos destacamos la obra, ya clásica, de C. J. Date (Date 1990). En este apartado resumiremos los conceptos más importantes del modelo relacional. Lo que exponemos a continuación es, en esencia, un resumen de la obra de Codd (Codd 1990).
Como ya hemos mencionado, el modelo relacional está basado en la teoría de conjuntos. En este modelo, los datos se organizan en un tipo especial de conjunto denominado relación, (relation) que se define de la siguiente manera: sean los conjuntos D1,..., Dn, denominados dominios, que no tienen por qué ser distintos entre sí. Una relación definida sobre D1,...,Dn es cualquier subconjunto R de D, donde n es el grado o aridad de R. Los dominios son en principio conjuntos finitos de datos. Por tanto, a menos que se indique lo contrario, presumimos que las relaciones son también finitas. Los elementos de una relación se denominan tuplas. Formalmente, una tupla es:
< d1,..., dn>, donde d1 ![]() D1,..., dn
D1,..., dn ![]() Dn
Dn
El número de tuplas en una relación es la cardinalidad
de la relación. Puesto que una relación es un conjunto, los elementos de este conjunto,
las tuplas, han de ser por fuerza distintas. Esto también implica que el orden de las
tuplas es irrelevante. El conjunto vacío es una relación particular: la relación nula
o vacía. Cada tupla de una relación, junto con el nombre de la relación,
representa una aserción (en el sentido lógico). Por ejemplo, cada tupla en la relación PROFESORES,
es una aserción de que la entidad (profesor) dx es miembro de la institución
Dx y tiene las propiedades atómicas <v1,..., vn>.14
Las relaciones también pueden ser vistas como tablas, en las que cada tupla es una fila de la tabla. Los nombres de las columnas de la tabla, por otra parte, son los atributos. El conjunto (ordenado) de todos los atributos de una relación R es el esquema de R. Nos podemos referir a los atributos de una relación mediante su nombre o por la posición (número de columna) que el atributo ocupa en el esquema de la relación. Las tuplas, por tanto, pueden ser consideradas como matrices de pares atributo:valor.
El dominio D de R es la colección de
valores posibles para un determinado atributo. Por ejemplo el dominio del atributo NOMBRE
en la relación "Asignaturas" serían todas las asignaturas que un centro
educativo ofrece a sus alumnos. Cada atributo debe tomar los valores de un dominio
subyacente, y sólo uno. Una buena implementación de una base de datos relacional debe
poner en marcha los mecanismos necesarios (en términos de diseño conceptual) para que
este tipo de restricciones puedan ser impuestas. El concepto de atomicidad es
ciertamente relevante en el contexto de las tecnologías de la información y
especialmente en el campo de las bases de datos. Que un elemento sea atómico (también
llamado escalar) implica que no puede ser descompuesto en partes más pequeñas.
Por ejemplo, a la hora de codificar un número de teléfono, tenemos varias opciones.
Podemos guardar la información como un único valor, en cuyo caso, los prefijos
interprovinciales y/o internacionales formarían parte indivisible del número; también
podemos optar por codificar la información en tres valores separados, uno para el prefijo
internacional, otro para el interprovincial y un tercero para el número de abonado. La
primera disposición, como un único valor, aunque sirva al usuario de la base de datos
para obtener la información precisa, presenta la desventaja de que no podrá ser usado,
por ejemplo, por un programa de comunicaciones para marcar el número y efectuar una
conexión (para voz, fax o datos) de forma automática.
Un dato, también puede ser compuesto, es decir puede ser descompuesto y hacerse uso de los datos atómicos que contiene (por ejemplo el tipo de datos de estructura de rasgos que mostramos en el capítulo anterior cuyos valores podían ser, a su vez, otras estructuras de rasgos). Ya hemos mencionado que en el modelo relacional todos los datos han de ser atómicos, aunque hay una excepción muy particular a esta regla: la relación, que es considerada como un tipo de dato compuesto. Sin embargo, la posibilidad de disponer de datos compuestos, sería muy deseable en un sistema de base de datos. A nivel de diseño, tal característica simplificaría notablemente la codificación de un esquema conceptual determinado.
Por otro lado, los lenguajes de programación de tercera generación (3GL) no estaban preparados para manejar este tipo de datos complejos. Lo ideal para manejarlos sería poder considerarlos tanto como un único objeto, como un número de individuos agrupados, de forma que según la ocasión se pueda acceder a uno o varios de ellos por separado o bien a todos ellos como un conjunto. La complejidad que implica manejar este tipo de datos mediante un 3GL es la causa de que el modelo relacional no implementase tipos de datos compuestos.
Los términos formales del modelo relacional a menudo son sustituidos por otros de uso más común, debido a que estos términos son demasiado abstractos para ser usados en la práctica. Así obtenemos las siguientes equivalencias (Date 1990):
Término relacional formal |
Equivalente informal |
| Relación | Tabla |
| Tupla | Fila o registro |
| Cardinalidad | Número de filas o registros |
| Atributo | Columna o campo |
| Grado | Número de columnas o campos |
| Clave primaria | Identificador único |
| Dominio | Fondos de valores legales |
Tabla 4.1 Términos relacionales y equivalentes informales
Aun así, deberíamos usar estos términos con gran cautela. Como Codd advierte (Codd 1990), el hecho de que las relaciones puedan ser percibidas como tablas, y puesto que una tabla es parecida a un fichero plano, puede crear la falsa ilusión de que la misma libertad de acciones permitida para las tablas o ficheros planos está permitida para la manipulación de relaciones. Por ejemplo en una relación no pueden existir dos tuplas exactamente iguales. Sin embargo, existen DBMS comerciales, supuestamente relacionales, tales como la familia dBase®, de Ashton-Tate (hasta su versión IV), y en general los productos xBase, que permiten este tipo de acciones no permitidas en enfoques relacionales puros.
En términos de representación tabular se dice que una relación consta de dos partes: cabecera (heading) y cuerpo (body). La cabecera es el conjunto de atributos (columnas) y el cuerpo es el conjunto de tuplas (filas). En la tabla 4.2, la primera línea (en negrita) es la cabecera y el resto de las filas el cuerpo.
ID
PROFESOR
CURSO
AÑO
DEPARTAMENTO
1
Date
Bases de datos
1991
Informática
2
Miller
Intro Psicolingüística
1994
Psicolingüística
3
Booch
Modelado semántico
1995
Informática
4
Sag
HPSG
1994
Lingüística
5
Sinclair
Lingüística de corpus
1990
Lexicografía
Tabla 4.2 Tabla, cabecera, cuerpo
En todo momento deberíamos ser conscientes de que los
elementos de una relación, como ya mencionamos, no tienen orden alguno, lo cual se
desprende del hecho de que una relación no es más que un conjunto matemático, con
algunas diferencias que exponemos más abajo. Así, la tupla con ID 1 no es la primera, ni
la ID 5 la última, la numeración de identificación es totalmente aleatoria,15 normalmente
resultado de un campo contador. Del mismo modo, los atributos tampoco tienen orden alguno;
el hecho de que el atributo PROFESOR aparezca antes que el de CURSO
en la sucesión de columnas no tiene relevancia alguna para la relación.
Como hemos mencionado, el concepto matemático de relación, puede resultar muy poco intuitivo y, como Codd (1990) recuerda, no se adapta a las definiciones de "relación" encontradas en los diccionarios.16 Se refiere a la propiedad de que una relación unaria (de grado o aridad uno), es una relación en sentido pleno. Así, una relación matemática de grado mayor que uno interrelaciona dos o más objetos, mientras que una relación de grado uno no. El tratamiento de una relación unaria es exactamente el mismo que el de una de mayor aridad.
Por otra parte, el concepto de relación en el modelo relacional presenta algunas diferencias con respecto a su correspondiente matemático. La Tabla 4.3 presenta estas diferencias de forma esquemática (Codd 1990).
Matemáticas |
Modelo relacional |
| Sin restricciones en el tipo de valores | Valores atómicos |
| Columnas sin nombre | Columnas con nombre |
| Distinción de columnas individuales por su posición | Distinción de columnas individuales por dominios y por nombres |
| Normalmente constantes en el tiempo | Normalmente varía con el tiempo |
Tabla 4.3 Relaciones en Matemáticas y en el Modelo Relacional
Además de la característica mencionada en cuanto a los tipos de valores, otra diferencia destacable (la tercera de las listadas en la tabla), es que mientras que ninguno de los dos tipos de relaciones está ordenado en cuanto a sus elementos (tuplas), una relación matemática está ordenada en cuanto a sus atributos (columnas), ya que éstas se distinguen por su posición. En el modelo relacional, al estar distinguidas por su nombre, su posición es totalmente irrelevante. Esta característica no es casual, sino que su objetivo es facilitar las operaciones con los atributos de las relaciones.
Finalmente, hemos de aclarar que relaciones no sólo son las "tablas" base de la base de datos, sino que también son los distintos tipos de relaciones que se pueden generar mediante consultas a las relaciones base. Podemos distinguir los siguientes tipos de relaciones:
Puesto que las tuplas son irrepetibles, una relación necesita un identificador único para cada una de las tuplas, esta es la clave (primaria) de la relación, que se define como un subconjunto C de los atributos de R, cuyos valores no pueden ser repetidos. Una clave primaria debe ser mínima, en el sentido de que en su composición no intervengan más que los atributos estrictamente requeridos para identificar las tuplas de forma única. Puesto que una relación es un conjunto de tuplas, se debe dar la condición de que toda relación deba tener una clave primaria; al menos el conjunto de los atributos de una relación conforma la clave de esa relación. Además, una clave primaria puede ser simple (formada por un solo atributo) o compuesta (formada por más de uno). Las dos características definitorias son, por tanto, la unicidad y la minimalidad (Date 1990).
La cuestión de si una clave primaria debe ser semántica o no sigue siendo fuente de discusiones. Una clave semántica, también llamada inteligente, es aquella que tiene significado por sí misma, independientemente de que sea o no la clave, es decir que el o los atributos que la conformen contengan valores que describan "realmente" a la entidad reflejada en la tupla (por ejemplo, los apellidos o el DNI en una relación que denote personas). Lo contrario, es decir, una clave arbitraria cuya única función es la de identificar la entidad designada por la tupla, se denomina clave subrogada.
Muchos proponentes del modelo relacional, entre ellos (Date 1991) opinan que usar una clave inteligente puede llegar a desorganizar una base de datos si se producen cambios en los datos y abogan por la utilización exclusiva de claves subrogadas; para estos autores este tipo de claves tiene el beneficio de poder ser modificadas con más facilidad. Otros autores no menos relevantes, como (Celko 1994), miembro del ANSI X3H2 Database Standards Committee, esgrimen sólidos argumentos a favor del uso de claves semánticas :
Particularmente pensamos que usar una clave semántica es una buena idea siempre que se tenga la absoluta certeza de que la situación generada por su utilización no es susceptible de cambiar con el tiempo y que realmente facilite el manejo de las relaciones en lugar de dificultarlo.
Sin embargo, nuestra experiencia particular nos lleva a pensar que el uso de claves subrogadas conduce a implementaciones más eficientes en la mayoría de las ocasiones. Creemos que la elección de una buena clave semántica conduce casi siempre a la utilización de claves compuestas, cuya indexación ocupa más espacio físico y entorpecen, cuando no imposibilitan, muchas operaciones. Por ejemplo, en la representación de un diccionario, una buena clave primaria podría ser la conjunción de LEMMA+SENSE, o LEMMA+PoS+SENSE. Habiendo probado esta disposición en implementaciones anteriores a la que vamos a mostrar en este trabajo (Moreno Ortiz 1995), esto ha demostrado ser una mala elección, ya que el lexicógrafo no tenía la libertad de modificar el identificador de acepción, por lo que hemos optado por una clave subrogada.
En otros casos no hay ningún atributo de la entidad que se pueda considerar como realmente definitorio de la misma y es más cómodo optar por una clave subrogada. Por otra parte, las claves subrogadas, al estar compuestas por un sólo número, ahorran espacio de almacenamiento, lo que hay que tener en cuenta cuando el sistema es susceptible de crecer.
En nuestra implementación la totalidad de las claves serán subrogadas, ya que la utilización de las mismas ha demostrado permitir una mayor flexibilidad en cuanto a las tareas comunes del usuario final y a las tareas de mantenimiento y modificaciones de esquema.
La polisemia del vocablo "relación" en español obliga a la utilización del término interrelación (relationship) para distinguir los dos sentidos ("relation"/"relationship"). De hecho, este problema semántico ha causado confusión en un buen número de estudiosos no especialistas en el campo. Un RDBMS ofrece la posibilidad de interrelacionar dos o más relaciones existentes en una base de datos. De hecho, es ésta la facultad que dota de mayor potencia al modelo. Hay varios aspectos que conviene resaltar sobre el establecimiento de interrelaciones.
En primer lugar, la manera en que el modelo relacional interrelaciona las relaciones existentes en una base de datos no es la que cabría esperar. Normalmente, cuando en una aplicación informática deseamos referenciar dos elementos cuales sea, utilizamos los denominados punteros (pointers), haciendo que un elemento apunte a la dirección de memoria de otro y/o viceversa. Sin embargo el modelo relacional funciona de forma diferente.
En realidad, no existe ningún tipo de puntero o enlace que el usuario pueda percibir. Todas las interrelaciones se realizan mediante la comparación de valores, ya sean éstos identificadores de objetos (claves primarias de las relaciones) o atributos de estos objetos. Para que esto sea posible, es condición indispensable que los valores a comparar pertenezcan al mismo dominio (y por tanto contengan el mismo tipo de datos (numéricos, texto, booleanos, etc.).17
Por otra parte, algunos RDBMS comerciales, (por ejemplo Microsoft AccessTM o ADABAS/D) permiten al usuario definir interrelaciones, incluso de forma gráfica. Pero esto no significa ningún cambio en cuanto a la estructura de la base de datos, sino que hace que el DBMS ayude más al usuario a la hora de hacer consultas, interrelacionando automáticamente las tablas incluidas en una consulta determinada y estableciendo las reglas de integridad referencial.
Por ello, una interrelación puede ser considerada a todos los efectos como otra relación (que normalmente se manifiesta como un conjunto dinámico de datos o una instantánea).18
La mejor manera de comprender como funcionan las interrelaciones en una base de datos relacional es mediante un ejemplo, que también nos ayudará a comprender la diferencia entre una relación y una tabla plana.
Consideremos la relación de profesores expuesta anteriormente en la Tabla 4.2. Sería conveniente que la base de datos a la que pertenece esta relación contuviese también información sobre los datos personales de los profesores, descripción de los cursos ofrecidos y descripción de los distintos departamentos. Pues bien si quisiéramos incluir toda esta información en una tabla plana, esta debería contener, al menos, los siguientes atributos (columnas):
PROFESOR_COD
PROFESOR_NOMBRE
PROFESOR_DIRECCIÓN
PROFESOR_TELÉFONO
PROFESOR_DEPTO
DEPTO_COD
DEPTO_NOMBRE
DEPTO_DESC
CURSO_COD
CURSO_NOMBRE
CURSO_DESC
CURSO_NIVEL CURSO_AÑO
La implicación directa de esta disposición es que el número de celdas que obtendríamos sería el resultado de
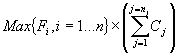
donde Fi representa el número de filas de la tabla i, Cj representa el número de columnas de la tabla j y n es el número de tablas que se obtendrían mediante un análisis relacional apropiado. La cantidad de información redundante sería totalmente inaceptable para una base de datos mediana. La información redundante no sólo implica mayor necesidad de almacenamiento masivo, sino también una ralentización de todas las operaciones con los datos. Imaginemos el resultado de una disposición como la anterior en bases de datos que contienen relaciones con cardinalidades del orden de decenas de millones.
El modelo relacional ofrece una buena solución a este
problema, que nos permite reducir la redundancia de datos al mínimo y agilizar las
operaciones de consulta y actualización. Lo que deberíamos hacer es separar la
información que se refiere a las tres entidades que tenemos (profesores, cursos y
departamentos) en tres relaciones independientes, y después relacionarlas entre sí. De
este modo obtendríamos una disposición parecida a la de la Figura 4.10. Los
recuadros indican relaciones base, mientras que las flechas indican las interrelaciones
entre ellas. Repetimos que estas interrelaciones, en realidad, no existen a nivel de la
base de datos, se usan sólo a nivel de representación gráfica.19 Los nombres de algunos
atributos (Prof_ID, Depto_ID, Curso_ID) sugieren el tipo de claves que hemos
usado: claves subrogadas.
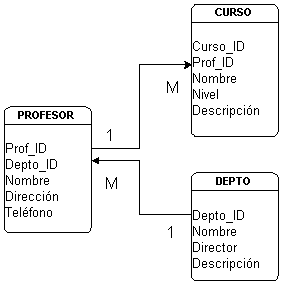
Figura 4.10 Ejemplo de disposición relacional
A partir de estas tres relaciones, y mediante el mecanismo de
comparación de valores que antes mencionamos, se tiene acceso a toda la información que
deseamos sin redundancia alguna. Los "1" y "M" que etiquetan las
flechas hacen referencia al tipo de interrelación "uno a muchos": en la
tabla PROFESOR no hay valores repetidos para el atributo Prof_ID
(existe un solo conjunto de atributos para describir un determinado profesor), pero
encontraremos varios de ellos en la tabla CURSO (un profesor puede dar varios
cursos). Igualmente, un departamento consta de varios profesores. Las interrelaciones que
hemos mostrado en la figura Figura 4.10 son todas del mismo tipo: de uno a muchos (one-to-many).
Ésta es la interrelación más frecuente. Además tenemos las de:
Las interrelaciones de uno a muchos se implementan mediante el uso de claves ajenas, también llamadas externas o foráneas (foreign keys). Una clave ajena es un atributo (posiblemente indexado y posiblemente compuesto) de una relación R2, cuyos valores han de concordar con los de alguna clave primaria en otra relación R1. R1 y R2 no han de ser necesariamente distintas.
Los atributos Prof_ID, en la tabla PROFESOR
, Curso_IDen la tabla CURSO y Depto_IDen la tabla DEPTO,
son claves primarias, mientras que los atributos Prof_ID en la tabla CURSO
y Depto_ID en la tabla PROFESOR, son claves externas.
Ahora que ya conocemos el funcionamiento de las claves primarias y las claves ajenas estamos en posición de estudiar las reglas de integridad. Con este nombre se designa aquellas reglas que han de ser aplicadas a una base de datos para asegurar que los datos introducidos sean consistentes con la realidad que pretenden modelar. Existen dos reglas generales que aporta el modelo relacional. Estas dos reglas son muy simples, y son las siguientes:
La primera de estas reglas impide la existencia de una tupla sin identificador único. La segunda impide que, por ejemplo, en nuestra base de datos académica, exista un profesor adscrito a un departamento inexistente, o un curso impartido por un profesor inexistente. Hemos de recordar que sólo los productos puramente relacionales implementan realmente estas dos reglas generales de integridad relacional. En otros, destinados al mercado doméstico, estas incongruencias son admitidas sin problemas.
Además, muchos RDBMSs añaden un buen número de características que ayudan al DBA a mantener más fácilmente la integridad de los datos. Mediante estos mecanismos es posible añadir reglas específicas para cada base de datos; éstas son las denominadas restricciones de integridad definidas por el usuario (Codd 1990). Por ejemplo, podríamos determinar que un profesor no pueda ser menor de x años o que un curso sólo pueda pertenecer a los niveles 1, 2 ó 3. El resultado sería que al intentar introducir un valor fuera de este rango, el DBMS rechazaría la información introducida mostrando un mensaje de error.
Además de las restricciones impuestas por las reglas generales del modelo relacional, y de las reglas específicas impuestas por el DBA para una determinada base de datos, sería conveniente la observación de otras "reglas" que reforzaran el modelo ayudaran a mantener la integridad de los datos y a evitar la redundancia. Esto es lo que se conoce como normalización.
Existen tres formas normales básicas, expuestas por Codd en la primera versión del modelo (Codd, 1972), conocidas como 1NF, 2NF y 3NF, respectivamente, más otras tres que fueron añadidas con posterioridad (BCNF, 4NF y PJ/NF ó 5NF). En realidad, BCNF (la forma normal de Boyce/Codd) (Codd, 1974) no es más que un intento de tapar los huecos de 3NF, y durante un tiempo fue llamada simplemente 3NF. Las dos restantes, 4NF y PJ/NF, no fueron definidas por Codd, sino por R. Fagin (Fagin, 1977 y 1979, respectivamente). A continuación exponemos sólo las tres formas normales básicas (las expuestas por Codd), pues la exposición de las tres posteriores implica un estudio previo necesario para comprenderlas, que pensamos se halla fuera de nuestros intereses en este trabajo.
- mutuamente independientes, y
- dependientes por completo de la clave primaria
Las formas normales han sido puestas en tela de juicio con posterioridad por la inconsistencia que algunas de ellas presentan frente a la información faltante. El mismo Codd, en la revisión de su modelo (Codd, 1990) dedica dos capítulos de su obra a este espinoso tema. La solución propuesta por Codd en esta revisión se basa en añadir una columna a las relaciones que llevaría una marca en caso de que la tupla en cuestión no proveyese ningún valor para ese atributo. Esta solución, si bien es perfectamente factible, no deja de ser un "parche", y a nivel conceptual no es "elegante". Además, esto requiere modificar el lenguaje de consulta ya estandarizado. De hecho las modificaciones propuestas por Codd no han sido llevadas a la práctica en RDBMSs comerciales.
Para crear las relaciones, modificarlas, eliminarlas, recuperar los datos almacenados en ellas, y para manipularlas en general, necesitamos un lenguaje formal que nos facilite el acceso, de lo contrario nos veríamos obligados a trabajar a bajo nivel, o nivel de máquina. Este lenguaje debe ser lo suficientemente expresivo para permitirnos llevar a cabo todas estas operaciones, y debe estar basado en formalismos que cumplan con todas las premisas expuestas en los apartados anteriores respecto a reglas de integridad, formas normales, etc. Existen dos tipos básicos de formalismos para expresar las consultas sobre las relaciones de una base de datos relacional: el álgebra relacional y el cálculo relacional
El lenguaje de consulta de bases de datos relacionales por antonomasia, es, como ya anticipábamos, el llamado SQL (Structured Query Language). Este lenguaje, basado en el álgebra relacional y el cálculo relacional anteriormente descritos, actúa de interfaz entre el usuario y la base de datos y facilita realizar todas las operaciones permitidas. El lenguaje fue diseñado para que, mediante un número muy reducido de comandos y una sintaxis simple, fuese capaz de realizar un gran número de operaciones. La curva de aprendizaje de SQL es realmente rápida. Además, SQL es bastante flexible, en el sentido de que cláusulas SQL pueden ser anidadas indefinidamente dentro de otras cláusulas SQL, facilitando así las consultas que utilizan varias relaciones, vistas u otras consultas.
Además de poder ser usado directamente, es decir, en modo comando, desde el DBMS, SQL puede ser usado desde otros lenguajes de programación de tercera generación, tales como C, para poder acceder a los datos de la base de datos y usarlos para cualquier fin en el programa. Cuando SQL es usado de este modo se le denomina SQL embebido (embedded). Esta característica amplía enormemente las posibilidades del modelo relacional. A continuación mostramos los conceptos fundamentales de SQL, pues mostraremos algunas líneas de instrucciones bastante complejas en el siguiente capítulo.
Las consultas en SQL constan de uno o más bloques de
recuperación SELECT-FROM-WHERE. El resultado de una consulta es siempre
una relación. La estructura es la siguiente:
SELECT atributos
FROM relaciones
[WHERE condiciones-lógicas]
SELECT corresponde a la operación de proyección del álgebra relacional.
Especifica todos los atributos que se desean recuperar.
FROM especifica una lista de relaciones de donde se escogerán los atributos de
la cláusula SELECT.
WHERE es opcional e incluye las condiciones que deben cumplir los atributos de las relaciones.
Ejemplos:
SELECT direccion, telefono
FROM profesor
WHERE nombre = "Miller"
Devolvería la dirección y el teléfono del profesor Miller.
SELECT nombre, director, desc
FROM depto
WHERE profesor IN
(SELECT prof_ID
FROM profesor
WHERE profesor = "Sinclair")
Devolvería el nombre, nombre del director y descripción del departamento al que pertenece el profesor Sinclair.
Además de estas cláusulas básicas, existen otros muchos
operadores que modifican los resultados, y que permiten acciones tales como mostrar
valores no repetidos (DISTINCT), unir, intersectar o restar filas en un
resultado (UNION, INTERSECT, MINUS), contar valores (, sumarlos (SUM),
agrupar por valores (GROUP BY, obtener máximos y mínimos (MAX, MIN
), promedios (AVG), ordenaciones (ORDER BY), etc.
Finalmente, SQL incluye tres comandos de actualización de
datos : UPDATE (modificar), INSERT (insertar) y DELETE
(eliminar).
Para concluir esta sección mencionaremos un sistema de consulta de bases de datos relacionales relativamente nuevo, el QBE (Query By Example), desarrollado originalmente por IBM bajo el sistema VM/CMS. El lenguaje QBE es un sistema relacional de manejo de datos basado en el cálculo relacional de dominios. Posee dos características principales que le distinguen :
Las más modernas aplicaciones combinan esta metodología con la tecnología de los GUI (Graphical User Interface) para ofrecer una evolución llamada GQBE (Graphical Query By Example). Sistemas que ofrecen estas posibilidades son, por ejemplo, Microsoft AccessTM, Microsoft Visual FoxProTM, Corel Paradox®, Oracle8 de Oracle® Corporation, ADABAS D, de Software AG o Sybase® SQL Anywhere. Además, algunos de estos sistemas, por ejemplo MS Access o ADABAS D, permiten combinar el SQL standard con GQBE, aumentando así la potencia y flexibilidad.
Durante la exposición en los apartados anteriores y el capítulo anterior de las bases de datos en general y el modelo relacional en particular, hemos comentado las características más sobresalientes de este tipo de sistemas de información. Las ventajas de utilizar un RDBMS podrían ser resumidas en las siguientes:
En general, un RDBMS cumple con los requisitos que expusimos al principio del Capítulo 4, por lo que parece una elección razonable. El RDBMS que hemos utilizado para nuestra implementación, Microsoft Access, cumple todas ellas, estando considerado, en su versión 8 (Access 97) como uno de los RDBMSs para estaciones de trabajo bajo plataforma Win32 más sólidos y versátiles del mercado, ofreciendo todas las garantías de conectividad y estabilidad deseables, así como uno de los motores de bases de datos más rápidos.
Sin embargo, también hemos de ser conscientes de los aspectos negativos, o más bien limitaciones, que conlleva la adopción un modelo de datos con una veintena de años. Existen una serie de desventajas bien conocidas del modelo relacional de datos, que se ponen de manifiesto especialmente cuando lo comparamos con otros modelos más nuevos (p. ej. el modelo orientado al objeto o las modernas implementaciones basadas en marcos). Las más obvias son las siguientes:
Los cuatro primeros aspectos afectan directamente a la representación léxica, mientras que el último es un problema meramente técnico que no detallaremos y que no presenta el modelo de datos orientado al objeto que hemos mencionado.
Como vimos en el apartado 4.4, los formalismos de representación léxica modernos hacen uso extensivo del concepto de herencia mediante mecanismos provenientes de los esquemas de representación basados en marcos. En este sentido son superiores en poder expresivo a una base de datos relacional, pero sin embargo no ofrecen las facilidades de manejo de datos masivos que una base de datos garantiza. El RDBMS que utilizaremos implementa una función avanzada del modelo relacional: la noción de tipo/subtipo, mediante la cual se puede recrear una jerarquía, aunque no con el poder expresivo de los lenguajes basados en marcos como el que mostraremos a continuación y con el que hemos implementado nuestra ontología. Se trata únicamente de un mecanismo de autoreferencia (self-joint) mediante el que se puede interrelacionar una relación determinada consigo misma. Utilizaremos este mecanismo para establecer nuestra "jerarquía" de dimensiones y subdimensiones dentro de un campo léxico.
En resumen, un RDBMS supone una plataforma estable y compatible, con limitaciones en sus capacidades y poder expresivo. En este estado de cosas, pensamos que un cuidado diseño (modelado conceptual) puede vencer muchas de estas desventajas y aprovechar al máximo todas las ventajas mencionadas. La evolución del modelo relacional pasa por los modelos semánticos de datos, o de cuarta generación. Estos modelos, influenciados por los sistemas de información de la IA, trataron de dotar de significado a las estructuras de datos. En el siguiente capítulo describiremos un modelo de datos semántico, el de Entidad/Relación (Chen 1976) que nos servirá para mostrar el modelado conceptual de nuestra base de datos. Consideramos esta línea de investigación como la verdaderamente revolucionaria en el terreno de las bases de datos, ya que ha permitido el desarrollo de sistemas de representación muy avanzados, entre ellos, y sobre todo, el modelo de orientación al objeto.20
No nos detendremos a analizar estos novedosos modelos aunque resultan ciertamente atractivos, especialmente tras las últimas revisiones de los estándares CORBA y la fijación del método unificado (Booch & Rumbaugh 1995) como estándar de modelado de datos.
En cualquier caso, para entender estos modelos de datos es necesaria una perspectiva de los esquemas de representación típicamente usados para desarrollar bases de conocimiento, porque la influencia de los últimos sobre los primeros es evidente y porque no es posible llegar a entender su alcance sin comprender las técnicas de IA puras de las que provienen. Hemos preferido contemplar el desarrollo de estos modelos de datos dentro del espectro de influencias mutuas entre las dos facetas de la representación de conocimiento que venimos estudiando: las bases de datos y las bases de conocimiento.
NOTAS
Anterior I Siguiente I Índice capítulo 4 I Índice General