



"Simulación Social: Una introducción" por Francisco J. Miguel Quesada
se encuentra bajo una Licencia Creative Commons Atribución 3.0 Unported.
“La simulación social multi-agente es una alternativa metodológica para avanzar en el conocimiento sociológico con vocación integradora, puesto que posibilita la articulación de teoría y empíria al permitir la realización de experimentos para verificar hipótesis, examinar supuestos o comprobar la veracidad y coherencia de los marcos teóricos.” (Arroyo & Hassan, 2007)
“Even the most sophisticated agent programs are probably less intelligent than an ant (...) Nevertheless, as we shall see, there are lessons that can be learned even from such apparently crude representations of people.” (Gilbert & Terna, 2000)
1. La simulación computacional como metodología de investigación
Según la actual concepción semántica de las teorías científicas, la representación y explicación de fenómenos sociales en CC.SS. implica la construcción de modelos explicativos, utilizando en cualquier caso algún tipo de sistema simbólico (Díez, 1997; Diez & Ulises, 2008). En la mayor parte de las ocasiones se trata de representaciones verbales, lo que suscita diversas cuestiones relevantes: ¿Cómo utilizar tales representaciones para estudiar sus implicaciones (especialmente, en relación con observaciones de la realidad distintas de las que dieron origen a los modelos teóricos verbalizados)?, ¿Cómo analizar sus posibles inconsistencias conceptuales o evaluar su validez interna?, ¿Cómo generalizar mediante inferencias tales teorizaciones hipotéticas?
Algunos modelos explicativos van más allá de la representación verbal y se expresan mediante ecuaciones matemáticas o estadísticas, lo que facilita las tareas de análisis de su consistencia, su generalización y su justificación empírica (contrastación). Esto de nuevo suscita interesantes cuestiones epistemológicas y metodológicas: ¿Cómo manejar tales sistemas de ecuaciones cuando son analíticamente intratables debido a su extrema complejidad?, ¿Cómo tratar con representaciones formales matemáticas de fenómenos que implican relaciones no lineales, o altamente sensibles a condiciones puntuales o contextuales?. Habitualmente la solución pasa por 1) utilizar un conjunto de asunciones fundamentales del modelo extremadamente simplificadas, primando la manejabilidad matemática sobre la plausibilidad sociológica [1] , al tiempo que 2) se defiende epistemológicamente la naturaleza esencialmente reduccionista y simplificada de cualquier modelo que represente un sistema.
Sin embargo, cabe hacer notar que estar de acuerdo con el mencionado principio epistemológico no implica necesariamente realizar el anterior tipo de operación reduccionista, pues el uso de un modelo matemático no es la única alternativa a los modelos verbales (Ostrom, 1988). Una tercera forma de representar un fenómeno social es mediante la construcción y puesta en funcionamiento de un sistema que simule sus propiedades, mecanismos, dinámica y resultados, esto es lo que se conoce como “simulación social”. Si el sistema simulador se construye y ejecuta en un dispositivo informático electrónico (bien sea un ordenador personal, o una red de cientos de ellos) se puede hablar de modelos de simulación social mediante ordenador.
La lógica para desarrollar estos modelos es similar a la utilizada en el desarrollo de modelos estadísticos. A partir de la observación de fenómenos propios de un sistema social se construye una representación del mismo, en forma de modelo matemático (e.g., red), estadístico (e.g., ecuación de regresión) o informático (modelo de simulación). A partir de la observación del “comportamiento” del modelo, y de la comparación de sus “resultados” con observaciones empíricas del sistema social, se atribuye un nivel de validez al modelo[2] . A partir de los resultados obtenidos se pueden realizar modificaciones del modelo (inclusión/exclusión de variables independientes no significativas, o modificaciones del código informático, según sea el caso) y generar nuevos “resultados” de forma repetida hasta que no se alcance ninguna mejora en términos de ajuste. A partir de la comparación del nivel de validez -o ajuste empírico- entre diversos modelos o versiones del modelo, se toma una decisión sobre el que representa de forma más justificada los fenómenos que se intentan representar. El resultado del proceso es la descripción/publicación del modelo en términos descriptivos: en el caso de un modelo estadístico puede tratarse del conjunto de coeficientes de regresión, y en el caso de un modelo informático puede tratarse del código informático en sí mismo, o de una representación formal de los algoritmos utilizados. En ambos casos es preciso aportar los correspondientes indicadores de ajuste empírico.
Por tanto, la simulación social puede considerarse una metodología de investigación, similar en cuanto a su lógica a otras modalidades de método científico en general, ya que consiste en 1) formalizar teorías complejas sobre determinados procesos sociales (Inferencia abductiva), 2) llevar a cabo experimentos a partir de la formalización construida (Inferencia deductiva), y 3) observar la generación de resultados emergentes de la formalización (Inferencia inductiva).
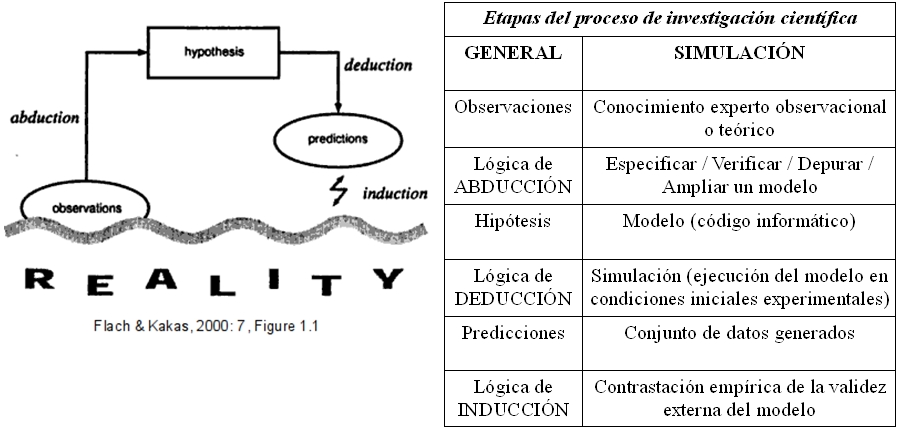
La especificidad propia de la SSMA es que las hipótesis explicativas toman la forma de código informático, o “modelo de simulación”, que puede ser ejecutado en un sistema informático. Tal especificidad puede ser acertadamente descrita brevemente como: ejecutar repetidamente un programa informático que replica un sistema social, modificando de forma planificada y sistemática sus parámetros iniciales mientras se registran los resultados de tal simulación, y comparar tales resultados con observaciones relevantes de ciertos indicadores del sistema objeto de estudio. Aunque existe diversidad de usos para las simulaciones informáticas, en el presente capítulo se considera como utilidad fundamental de la simulación social el desarrollo de teoría social dentro de un proceso de investigación. La mayor parte de la comunidad de investigadores sociales practicantes de SS consideran su principal utilidad la de evaluar la validez o calidad interna de hipótesis explicativas, a diferencia de lo que ocurre dentro de la comunidad de ingeniería en la que se considera su principal utilidad la predicción de escenarios futuros (Gilbert & Troitzsch, 2006: cap. 1; Miguel, 2009).[3]
2. La simulación social computacional: definición, orígenes y modalidades históricas
Para caracterizar convenientemente la simulación computacional, conviene aclarar la distinción entre modelización, simulación y sistema experto. El proceso se modelado implica la transcripción a un formalismo computacional de la descripción conceptual de mecanismos que gobiernan o rigen el comportamiento de un sistema real. Una modelización en sentido computacional es simplemente un conjunto de lineas de código informático en alguno de los lenguajes de programación disponibles, si tal código se ejecuta realmente en un sistema informático se tratará de una simulación. Un sistema experto implica la modelización de un fenómeno real, y la ejecución del modelo para generar resultados simulados, pero siempre con a) la presunción de que la modelización es enteramente válida y reproduce correctamente los resultados del sistema real, y 2) con la intención de obtener resultados o respuestas del sistema simulado que substituyan los que podrían obtenerse del sistema real. En todo el proceso descrito, la modelización (que expresa el sistema real) sería el momento inicial y el sistema experto (que substituye al sistema real) sería el momento final. La simulación es un proceso que permite aproximarse al conocimiento del funcionamiento de un sistema real más allá de su mera representación pero sin alcanzar a substituirlo. Se propone así una definición instrumental, esto es, la simulación computacional como una metodología de investigación y también como una estrategia de mejora e intensificación de la calidad de las prácticas de investigación. En este sentido, en general se puede entender la simulación como “el proceso de diseñar un modelo de un sistema real y llevar a término experiencias con él, con la finalidad de comprender el comportamiento del sistema o evaluar nuevas estrategias -dentro de los limites impuestos por un cierto criterio o un conjunto de ellos- para el funcionamiento del sistema” (Shannon, 1975). La simulación social computacional no es sino un caso particular de simulación, en la que 1) el modelo es un sistema informático, y 2) el objeto modelado y simulado es un sistema social que genera fenómenos sociales.
El presente texto mencionará la simulación social en dos sentidos: 1) la ejecución de un modelo computacional concreto con determinados parámetros o valores iniciales, y 2) una variante metodológica particular del proceso de investigación social general. A pesar de ello, está dedicado especialmente a la segunda acepción: a la metodología de investigación social utilizando simulación social basada en agentes, o multi-agente (SSMA), esto es, una de las diversas modalidades históricas de simulación social computacional.
El estudio de procesos sociales mediante su modelado y su simulación se ha realizando desde hace siglos[4] , aunque las aportaciones iniciales consideradas más relevantes se centran en el desarrollo de las ecuaciones diferenciales en el siglo XVIII y, algo más tarde, los procesos estocásticos (Troitzsch, 1997). De hecho, el origen de las modalidades actuales de simulación social puede reconocerse en el desarrollo durante la primera mitad del siglo XX de diversas áreas de la matemática aplicada que permiten modelizar interacciones sociales y procesos de decisión en el contexto de estructuras formalizadas (Davis, 1971), como por ejemplo la teoría matemática de los juegos de estrategia, la de autómatas celulares o la de redes sociales (Lozares, 2004). Como aportación genérica de tales desarrollos matemáticos a la orientación general de la actual simulación social asistida por ordenador cabe destacar el hecho de que estas “nuevas” orientaciones matemáticas simulan sistemas dinámicos que evolucionan en el tiempo en pasos discretos. Aunque existen también ejemplos precursores de simulaciones sociales físicas -por parte de Irving Fisher en 1893 (Brainard & Scarf, 2005), o Bill Phillips en 1949-, el desarrollo tecnológico más relevante para la simulación social ha sido el relacionado con el procesamiento digital de la información, esto es, el desarrollo de la tecnología de máquinas computadoras digitales desde 1940, incluyendo los avances en tecnología de la programación (orientada-a-objetos, distribuida, lenguajes de alto-nivel) por parte de las ciencias de la computación y la inteligencia artificial.
Cuatro son las modalidades históricas de simulación social computacional que reconoce ampliamente la literatura (Gilbert & Troitzsch, 2006): la simulación de flujos poblacionales (System Dynamics, SD), la simulación de flujos de sucesos (Stochastic Processes, SP), la simulación de comportamiento individual interactivo (Cellular Automata, CA) y la simulación de sistemas de interacción basada en agentes (Multi-agent based Systems, MABS).
(SD) DINÁMICA DE SISTEMAS: A lo largo de la década de 1960 comenzó la simulación por ordenador en las universidades utilizando sistemas de ecuaciones diferenciales para representar las trayectorias de variables en el tiempo (Hanneman, 1988). Esta aproximación (conocida como “dinámica de sistemas”) permite modelar cualquier sistema que pueda representarse mediante ecuaciones diferenciales, esto es, cualquier sistema cuya dinámica se conozca previamente. La “interacción” en tales sistemas es modelizada como proceso que afecta a sujetos o elementos considerados como un todo, como poblaciones con flujos demográficos gobernados por el sistema de ecuaciones que define y determina el sistema.
(SP) PROCESOS ESTOCÁSTICOS: Otros tipos de simulación se desarrollaron tras la aparición de los ordenadores y el desarrollo de elevadas capacidades de cálculo aplicadas a procesos que tienen comportamientos agregados con efectos en diversos niveles (simulación multi-nivel, Helbing, 1994) o procesos con indeterminaciones en los tiempos de ejecución (simulación de colas, Kreutzer, 1986). En este caso, la “interacción” en el sistema tiene lugar entre los eventos que suceden, no entre los individuos.
(CA) AUTOMATAS CELULARES: Un espacio matemático (p.e., una cuadrícula regular) donde cada célula posee, en cada momento, un estado discreto seleccionado de un número finito de estados posibles permite simular diversos fenómenos sociales. En un CA cada célula tiene una “vecindad” constituida por un conjunto finito de células en su cercanía inmediata y tiene igualmente conciencia del estado de cada una de sus células vecinas. Tras iniciarse la simulación, para cada paso discreto de tiempo el estado de cada célula se actualiza mediante una función de transición (homogénea) basada en el estado de la célula en cuestión y en el estado sus vecinas (Von Neumann, 1966).[5] La conjunción de esta perspectiva y la teoría matemática de los juegos de estrategia permite plantear y estudiar problemas sociales mediante la construcción, puesta en marcha y análisis, de sociedades artificiales, formadas por un número de autómatas celulares en interacción (Hegselmann, 1996). Ejemplos clásicos de tales estudios son la emergencia de entidades políticas como imperios o alianzas a partir de la agregación de otras menores (Axelrod, 1995), o el voto por mayoría (Capcarrere, 1996).
(MAS) SISTEMAS MULTI-AGENTE: En la década de 1990 se desarrolla una nueva aproximación dentro de la Inteligencia Artificial, relacionada con la llamada “IA distribuida”, “inteligencia social” o “de enjambre” (Schut, 2007). Mientras que el objetivo de la IA clásica fue imitar el funcionamiento del cerebro humano, la nueva IA distribuida pretende resolver los problemas a los que se enfrenta desarrollando entidades autónomas e interdependientes que generan “inteligencia colectiva” a partir de la interacción entre elementos simples (Ferber, 1999). La aplicación de esta nueva perspectiva a la simulación social permite la creación de sistemas de interacción de numerosos agentes autónomos en cuanto a sus objetivos, así como con capacidades cognitivas y comunicativas ampliadas (Gilbert & Troitzsch, 2006). La definición conceptual de agente de software mínima comúnmente aceptada es “un programa informático autocontenido que puede controlar sus propias acciones, basado en sus percepciones del entorno” (Huhns & Singh, 1997). La mayoría de autores considera que los agentes son entidades AIRP (Wooldridge & Jennings, 1995), esto es: A) autónomos -pueden operar sin el control directo de humanos u otros agentes-, I) interactivos -con habilidad social para relacionándose con su entorno y/o otros agentes-, R) reactivos -perciben su entorno y responden en consecuencia-, y P) proactivos -pueden tomar la iniciativa, con comportamiento basado en objetivos-. Otras características de los agentes en sistemas MAS es que tienen conocimiento local -perciben únicamente parte de su entorno próximo-, percepción subjetiva y racionalidad limitada, capacidad de ser programados para simular procesos de adaptación, de aprendizaje, planificación sofisticada y lenguaje entre ellos. Los agentes pueden ser entidades individuales o colectivas humanas -grupos, familias, empresas, naciones, etc.-, así como cualquier objeto físico animado o inanimado, e incluso es posible -y puede ser conveniente en determinadas investigaciones- modelizar como agentes ciertas entidades inmateriales como enunciados, creencias, deseos, normas, reglas de comportamiento, e incluso vínculos entre agentes.
Las primeras modalidades históricas de simulación (SD, SP) resultan, en general, más apropiadas para modelizar sistemas centralizados, dominados más por leyes físicas o protocolos rígidos que por procesos de información, mientras que las más recientes modalidades (CA, MAS) ofrecen mayor potencial para representar fenómenos propios de los dominios caracterizados por un alto grado de localización y distribución, como son las redes sociales (Arroyo & Hassan, 2007).[6] A pesar de ello, algunos desarrollos actuales desdibujan esta tradicional diferenciación: existen herramientas de simulación capaces de modelizar según ambas lógicas (Netlogo), incluso utilizarlas ambas dentro del mismo modelo (Anylogic) y algunos autores proponen precisamente la doble modelización como metodología para incrementar la calidad del proceso de investigación (Izquierdo et al., 2008).
3. Elementos de los modelos sociales multi-agente (MSMA): Entorno, Agentes, Reglas
Los modelos de simulación basados en agentes derivan su desarrollo del campo específico de la inteligencia artificial distribuida (IAD): para la resolución de un problema concreto, una programación basada en agentes debe generar una “sociedad virtual” de programas informáticos intercomunicados entre sí, cada uno de los cuales posee un determinado y específico tipo de conocimiento y habilidades, que se coordinan en el momento de la ejecución del programa de forma que la combinación de sus decisiones y acciones resulta mejor que la solución que podría aportar un único programa “experto”. La modalidad distribuida de resolución de problemas se inspira en la aproximación general de la “inteligencia colectiva”, en la que numerosos agentes simples intercomunicados generan comportamientos y soluciones altamente satisfactorias a partir de reglas de comportamiento individual relativamente simples (Schut, 2007).
Se han sugerido diferentes esquemas generales para diseñar simulaciones sociales (entre muchos otros, Moss et al., 1988; Gilbert & Troitzsch, 2006), como por ejemplo el esquema ERA (Environment-Rules-Agents) de Gilbert & Terna (2000). La propuesta ERA mantiene en diferentes niveles conceptuales el “entorno” (E), los “agentes” (A) y las “reglas” (R). El “entorno” modeliza el contexto físico o medioambiental de la simulación, mediante un conjunto de reglas propias que gobiernan la dinámica de los atributos generales del espacio físico del modelo. Los “agentes” modelizan individuos -o entidades decisorias socialmente relevantes según la investigación en curso- mediante sus atributos particulares. Pueden existir diversos tipos de agentes, cuyo comportamiento es determinado por diferentes conjuntos de reglas de comportamiento (“Rule Masters”). Estos agentes no se comunican directamente entre sí, sino a través del entorno; así, cada agente sólo tiene acceso directo a sus vecinos. El comportamiento de cada agente es determinado, según el tipo, por el correspondiente Rule Master, que es un “objeto” en el sentido computacional del término y puede interpretarse como una representación abstracta de la cognición del agente.[7] Para poder modelizar los procesos de aprendizaje, y otras dinámicas normativas que implican modificaciones en los “Rule Master”, estos quedan determinados por otros objetos (“Rule Makers”) que funcionan como meta-reglas del sistema. La ventaja principal de esquemas como este es su modularidad, que permite a los programadores modificar por separado y sin excesivo coste de codificación cualquiera de los elementos.
Entorno
En el caso de la simulación social resulta obvio que los agentes deben operar dentro de entornos físicos y también sociales, esto es, dentro de una red local de interacción con otros agentes y dentro de un sistema institucionalizado de constricciones normativas (desde normas sociales difusas o convenciones culturales, hasta leyes respaldadas por la fuerza física). La construcción de MSMA permite implementar, adicionalmente, el entorno físico que impone a su vez constricciones sobre los agentes. De esta forma, es posible incorporar fácilmente a un SSBA recursos naturales animados e inanimados, artefactos producidos y utilizados por agentes, e integrarlo con sistemas de información geográfica (GIS). En los casos más simples, la mera ubicación espacial permite simular procesos en los que la conectividad o vecindario entre agentes resulta relevante, según la presunción habitual de que los agentes cercanos pueden interactuar o influenciarse mutuamente de forma más intensa que los alejados espacialmente. Tales modelos se suelen inspirar en técnicas relacionadas con la modelización mediante autómatas celulares (Hegselmann, 1996). En realidad, lo dicho para los agentes resultará aplicable al entorno puesto que es modelizado también mediante agentes de software.
Agentes
Como se ha visto, tanto los individuos sociales como el entorno, que ofrece constricciones a los individuos y a sus acciones, están representados por programas informáticos (software agents) que se integran y coordinan dentro de un sistema de IAD basado en la lógica de la “inteligencia colectiva”. Así, estos agentes son entidades “inteligentes” en el sentido que pueden:
- determinar la situación que les rodea (percepción situada),
- acceder a una lista de posibles comportamientos que responden a condiciones situacionales diversas (realización situada),
- recordar sus propios estados anteriores (memoria),
- acceder a una lista de reglas que determinan el comportamiento a realizar en función de los estados percibidos actuales y recordados pasados (planificación).
Esto permite caracterizar los MSMA, en contra del resto de modalidades históricas mencionadas y en función de las capacidades propias de sus unidades mínimas y fundamentales, los agentes. Así, una SSMA implica:
- Crear múltiples agentes de diversos tipos dentro del mismo modelo,
- Dotarles de heterogeneidad tanto en cuanto a sus atributos individuales como a sus reglas de decisión y acción,
- Gobernar sus acciones sin necesidad de racionalidad perfecta u optimización,
- Ubicar las acciones e interacciones dentro de un medio ambiente (situado cada agente en una sistema de coordenadas, en un espacio geográfico o en una red social con una topología concreta),Permitir la movilidad de los agentes, incluyendo constricciones del entorno,
- Representar los mecanismos de aprendizaje de reglas de comportamiento de los agentes,
- Representar el contenido y los procesos cognitivos de los agentes,
- Modelizar directamente las interacciones entre agentes (ya sea mediante simples transferencias de datos de agente a agente o través de formas simplificadas de lenguaje),
- Reconocer la emergencia o generación de resultados y comportamientos agregados.
La puesta en funcionamiento, o ejecución, de un modelo social multi-agente (MSMA) con un conjunto concreto de parámetros y valores iniciales tendrá como consecuencia la generación de resultados que emergen de la interacción entre los elementos del sistema SSMA. Precisamente, la experimentación social mediante simulación multi-agente ofrece la posibilidad de estudiar la emergencia de comportamiento agregado o colectivo en dos sentidos: 1) emergencia inesperada, cuando se espera algún estado de equilibrio del sistema y se detecta un comportamiento cíclico cuyos determinantes están implícitos en la estructura del modelo, y 2) emergencia impredecible, cuando se manifiesta un comportamiento caótico del sistema social.[8] Igual que en el caso de los sistemas naturales, en los sistemas sociales los fenómenos emergentes en el nivel macroscópico afectan a su vez a los componentes de nivel microscópico. Sin embargo, contrariamente a los sistemas naturales, en los que esta afectación es de naturaleza causal, en los sistemas sociales los resultados de procesos de acciones agregadas tienen una influencia temporalmente posterior tanto de naturaleza causal como de naturaleza cognitiva sobre los agentes. Los agentes que constituyen sistemas sociales reales tienen capacidad de reconocer, de deliberar al respecto y de reaccionar ante las instituciones sociales que emergen de los procesos constituyentes de la vida social, lo que implica la necesidad adicional de modelizar su sistema cognitivo mediante la implementación de algún tipo de sistema de representación de la realidad social. Esto es, dotarlos de un “mapa social”, o una “cognición situada”, tan relevante para la simulación social como irrelevante para la simulación física.[9]
Respecto a la construcción de MSMA, no existe actualmente ningún acuerdo sobre la forma “correcta” de construcción de sistemas sociales multi-agente. Tan sólo en función de los objetivos perseguidos por cada simulación concreta (Gilbert & Troitzch, 2006) diversas metodologías o aproximaciones de diseño resultan preferibles a otras. En todo caso, el conjunto de elementos mínimos requeridos por cualquier MSMA debe incluir mecanismos para: 1) percibir el estado del entorno (inputs), 2) almacenar inputs y acciones pasadas, 3) planificar acciones futuras, 4) llevar a cabo acciones sobre el entorno y 5) generar resultados(outputs). Los primeros cuatro tipos de mecanismos atañen fundamentalmente a los agentes sociales, mientras que el último permite modelizar los efectos sociales y agregados de las acciones individuales, y por tanto atañe al sistema en un sentido macroscópico. En este sentido existen diversas soluciones técnicas computacionales alternativas para programar “agentes de software” dotados de las características indicadas (Gilbert, 2008): 1) lenguajes de programación orientados-a-objetos, 2) sistemas de reglas de producción o 3) redes neurales artificiales[10]. Estas técnicas no son mutuamente excluyentes; pueden ser utilizadas en un mismo modelo de simulación para implementar agentes u otros elementos simulados, como el entorno, la aleatoriedad o incluso el tiempo.
Las dos arquitecturas computacionales más habituales para construir agentes de software corresponden a dos aproximaciones contrapuestas, pero con posibilidad de hibridación (e.g., Klüver (1998), o AnyLogic). Por un lado está disponible el paradigma simbólico de la inteligencia artificial clásica y los algoritmos para la resolución de problemas basados en “sistemas de producción”, y por otro lado las aproximaciones no-simbólicas, basados en aprendizaje (p.e., redes neuronales o algoritmos genéticos).
Reglas
Siguiendo el paradigma de los sistemas de producción, la modelización de procesos sociales puede fundamentarse en la idea básica de “disparo de mecanismos”, según una perspectiva cercana a la llamada sociología analítica (Hedström & Bearman, 2009; Hedström &Ylikoski, 2010; Macy et al., 2011; Manzo, 2011). Así, el concepto epistemológicamente aceptado y fiable de mecanismo (Bunge 2004) permite fundamentar la construcción de sistemas SSMA, juntamente con la idea específica de causación generativa implicada (Harré 1972: 116, 121, 136-137). Un sistema de producción es una técnica computacional simple y eficaz para diseñar un sistema basado en agentes sociales, construido a partir de tres componentes: un conjunto de reglas, una memoria de trabajo y un interprete de reglas. Cada regla consiste en dos partes: una condición, que especifica la situación en la que se “disparará” o ejecutará la regla, y una acción, que especifica las consecuencias de la ejecución de la regla. Un ejemplo de regla de producción para modelizar el proceso de satisfacción de deberes fiscales puede adoptar la forma siguiente:
- (condición) ahora está abierto el plazo temporal estipulado institucionalmente para el pago del tributo T, y
- (condición) la situación económica actual del agente A corresponde con lo estipulado institucionalmente para el pago del tributo T, y
- (condición) el agente A no concibe ninguna alternativa viable para evitar el pago del tributo T,
- (acción) entonces, el fondo fiscal se incrementa en T, y
- (acción) entonces, los recursos de A se decrementan por la cuantía de T, y
- (acción) entonces, el agente A actualiza su nivel interno de satisfacción con el sistema fiscal en una cuantía f(T).
Esta regla especifica una condición compuesta por elementos que hacen referencia a elementos tanto de estado del sistema general (plazo abierto), como de estado material de agentes concretos (situación económica) y de estado mental de agentes (pago). Igualmente, la parte de acción de la regla implica tanto elementos materiales del sistema (fondo fiscal), como elementos materiales de agentes (recursos) y estados mentales de agentes (satisfacción). Tales estados del sistema y de cada agente se representan simbólicamente en la memoria de trabajo, que es utilizada para evaluar las condiciones y también es modificada por las acciones.
Esta puede ser una más de las muchas reglas que, en conjunto, permiten especificar un modelo de simulación fiscal, junto con otras más simples en el sentido de implicar menos elementos; por ejemplo, “(condición) el agente A recibe una penalización fiscal por impago del tributo T, (acción) el agente A decrementa su nivel interno de satisfacción con el sistema fiscal en una cuantía f(T)”. La función del interprete de reglas es considerar cada una de las reglas, resolver conflictos, disparar aquellas que cumplan la condición especificada, realizar las acciones indicadas por las reglas ejecutadas y repetir este ciclo a lo largo del tiempo de la simulación. Un sistema de producción simple permite diseñar sistemas sociales con agentes meramente reactivos al entorno, pero puede complicarse el conjunto de reglas hasta conseguir modelos cognitivos en los que los agentes estén dotados de capacidad para modificar sus propias reglas de producción mediante algún tipo de algoritmo adaptativo que recompense o penalice ciertas reglas en función de los resultados percibidos de las acciones asociadas a tales reglas (p.e., Ballot et al, 1999; Holland & Miller 1991).
Las reglas de producción correspondientes a la dinámica de un sistema simulado sustituyen la función “generatriz” que, en otras modelizaciones cuantitativas, cumplen los sistemas de ecuaciones de diferencias, o los pesos de los nodos de redes neuronales, o los coeficientes de modelos econométricos, de análisis multivariente o de ecuaciones estructurales. Sin embargo, como destaca Lozares (2004), las representaciones mediante modelos de simulación acostumbran a ser más similares a los procesos del mundo real que los provenientes de otros modelos matemáticos, y cabe añadir, que sus elementos generativos resultan cualitativamente más comprensibles y más cercanos a hipótesis teóricas para el científico social. En este mismo sentido, se ha destacado como beneficio de trabajar con simulaciones multi-agente la facilidad de resolver el problema de establecer la direccionalidad causal en la dinámica del fenómeno estudiado (Arroyo & Hassan, 2007) . No es preciso el uso de ecuaciones, y por tanto ni resulta necesario la definición previa de variables independiente y dependiente, ni se incurre en ningún tipo de circularidad matemáticamente irresoluble.
Una aproximación alternativa, y más compleja, a la modelización de la dinámica de reglas que gobiernan el comportamiento de cada agente es construir agentes capaces de un tipo de aprendizaje más fundamental que la simple actualización de su memoria de trabajo. Se trata en este caso de que la estructura interna de procesamiento de la información se adapte a circunstancias cambiantes del entorno. La literatura al respecto se centra en dos técnicas habituales de programación utilizadas para construir tales agentes: redes neuronales y algoritmos genéticos, como caso especial de algoritmos evolutivos. Tales técnicas de simulación inspiradas en analogías biológicas como la conectividad neuronal humana o los procesos evolutivos a muy largo plazo, suponen sin duda un incremento de realismo en cuanto a la modelización de las estructuras mentales de los agentes sociales, y aunque pueden resultar interesantes para determinados ámbitos concretos de investigación, para la mayoría de los casos de SSMA deben ser cuidadosamente evaluadas, en cada caso, en relación al esfuerzo de programación que suponen y a la complejidad añadida del posterior análisis de los resultados.[11]
5. Modelado y simulación social: Una guia práctica
En un intento de ofrecer una guía para la práctica de esta modalidad metodológica, diversos autores han presentado el proceso de investigación social mediante modelos multi-agente como un protocolo o secuencia de etapas (“e*plore methodology” de Antunes et al., 2007; Gilbert, 2008: 30-46). A continuación se repasan sistemáticamente los momentos más destacados de esta secuencia, insistiendo especialmente en las preguntas pertinentes a resolver en cada etapa. El protocolo aquí presentado debe entenderse como una idealización de las prácticas habituales en la comunidad académica dedicada a SSMA. De forma similar a la investigación científica en general, algunas de estas etapas en realidad se llevan a cabo de forma paralela y la mayoría de ellas se realizan recursivamente con saltos a etapas “anteriores” conforme el proceso de modelado, de simulación y de contrastación avanza, se refina y se amplía.
1. Formular la pregunta fundamental y “lluvia de ideas” inicial
Conviene comenzar el proceso pensando en cómo capturar los elementos esenciales del sistema social o fenómeno que se está intentando modelar: ¿Cual es la pregunta fundamental a la que el modelo pretende aportar explicaciones? ¿Cómo va a ayudar la simulación a comprender mejor la cuestión estudiada? ¿Qué es lo que se va a modelizar, una situación o un proceso? ¿Qué nivel de precisión o detalle son relevantes para comprender el problema? ¿Qué se incluirá en el modelo y qué quedará excluido?. En el caso de estudios sociales interdisciplinares una primera fase conjunta de aportaciones libres ayuda a establecer las pautas de trabajo del equipo, mejorando en cualquier caso la calidad de la modelización. En el caso de estudios unipersonales, las aportaciones pre-teóricas o “metafóricas” promueven la apertura del proceso mental fundamental que debe guiar las primeras fases del procedimiento de modelización, esto es, la inferencia abductiva.
2. Relacionar las ideas con la teoría
Conocer las teorías previas que hacen referencia al fenómeno o situación que se desea simular: ¿Cual es el fenómeno a explorar? ¿Qué teorías específicas existen para explicar el fenómeno a estudiar? ¿Qué teorías generales existen para explicar el comportamiento de posibles elementos del modelo? ¿Qué es central y qué es accesorio en la explicación? ¿Qué es central y qué es accesorio en la modelización? ¿Qué teorías ayudan a entender en qué forma se “generar” el (macro)resultado observado?. Como se detalla en el posterior apartado 5, ciertos conjuntos de teorías de las ciencias sociales son más adecuadas para aproximaciones a la simulación en su modalidad “dinámica de sistemas” -las de carácter estructuralista, holista o idealista-, mientras que otras son especialmente adecuadas para la simulación multi-agente -las de carácter materialista, individualista o generativa- (Hëdstrom & Ylinovsky, 2010: 62, Hedstrom & Bearman , 2009; Macy & Flache, 2009) incluidas teorías decisionales como el paradigma DBI.[12]
3. Construir teóricamente el modelo formal (hipótesis)
Se trata a continuación de desarrollo las hipótesis sobre cómo construir el sistema de simulación, en términos de sus elementos y sus relaciones, así como los intercambios de energía e información entre los distintos elementos y los mecanismos que rigen tales cambios de estado.
3.1) ¿Cuales son los agentes del sistema? ¿Qué atributos tienen? ¿Existen tipos de agentes? ¿Qué reglas se aplican a cada tipo?
3.2) ¿Cual es el ambiente o base física del sistema? ¿Qué elementos contiene? ¿Pueden considerarse agentes? ¿Qué supuestos afectan a esta base física o ambiental?
3.3) ¿Que relaciones existen entre los agentes? ¿Qué relaciones existen entre agentes y ambiente? ¿Qué mecanismos permiten modelizar y simular generativamente el resultado de todas estas relaciones?
4. Formalizar del modelo
En este momento del desarrollo del modelo es de gran ayuda la utilización de formalizaciones que permitan expresar los elementos del modelo y sus relaciones, por ejemplo, mediante diagramas del Lenguaje Unificado de Modelización o UML (principalmente, diagrama de clases, de secuencias y de actividades) (Grimm et al., 2006; Bommel & Müller, 2007; Fonseca, 2009). En todo caso, un diagrama de actividades o diagrama de flujo resulta una guía imprescindible para a) desarrollar todo el proceso posterior de la programación informática del modelo, o b) comunicar eficientemente a un programador externo las especificaciones del modelo que se desea construir, y c) especificar claramente el modelo de cara a la posterior comunicación y publicación de resultados.[13]
5. Codificar y documentar el modelo informático
El objetivo es convertir la especificación del modelo como hipótesis en un conjunto ejecutable de lineas de código informático. Dado que existen diversos lenguajes de programación y dado que, aún con el mismo lenguaje, hay diversas formas de implementar cualquier modelo, no se puede determinar una única solución para el problema de la especificación.[14] Todo modelo de simulación requiere de dos procesos generales para conseguir resultados derivados de su ejecución:
- 5.1) Inicialización del modelo, esto es, generar su situación o estado en el momento inicial de la simulación. La inicialización del modelo en ocasiones interesa que sea generada a partir de una función aleatoria (p.e., distribución uniforme de recursos, o ubicación aleatoria de la población de agentes), mientras que en otras ocasiones interesa replicar un estado empírico (p.e., SIG, o estructura poblacional censal), aunque la mayoría de modelos en su calidad de experimentos sobre teorías de rango medio (y no como facsímiles de la realidad) utilizan representaciones empíricas “estilizadas” o “simplificadas” e incorporan tanto valores iniciales aleatorios como empíricos. La inicialización se construye a partir de diagramas de clases o de casos.
- 5.2) Dinámica del modelo, esto es, ejecutar las reglas de desarrollo, cambios de estado, tomas de decisiones, acciones e interacciones, actualizaciones, aprendizaje, creación/difusión y demás fenómenos que componen la simulación y generan el fenómeno a estudiar. Esta es la parte principal de cualquier modelo de simulación social generativa, y contiene la implementación en forma de código informático de todos los mecanismos (físicos, biológicos, psicológicos y sociales) que, derivados de teorías al respecto, se han aceptado y seleccionado como parte de las hipótesis explicativas del fenómeno. En la aproximación a la simulación social basada en agentes cognitivos y situados, estos mecanismos o reglas de comportamiento deben ser genéricos y no deberían presuponer estructuralmente el resultado sino en cuanto a imponer constricciones amplias: esta modalidad de simulación social [15] pretende obtener resultados de complejidad social a partir de la multiplicidad de interacciones entre agentes regidos por sistemas de reglas simples. La dinámica del modelo se construye principalmente a partir del anterior diagrama de actividades o flujo.
En cualquier caso, es conveniente documentar el código en el momento mismo de escribirlo, esto es, detallar explícitamente el sentido de cada procedimiento y declaración empleada en la implementación del modelo. El objetivo no es otro que facilitar que cualquier persona pueda seguir la lógica de la implementación, en referencia a un equipo de codificadores que trabajen conjuntamente, o a la comunicación científica definitiva del modelo, o al propio codificador en revisiones posteriores. A tal efecto, la mayoría de los lenguajes de programación y entornos de simulación permiten adjuntar comentarios no-ejecutables entre las lineas de código, aunque también es práctica habitual y recomendable mantener actualizado un diario o registro histórico de cada modificación del código en un fichero informático adjunto al propio código.
6. Verificar la calidad interna del modelo de simulación
En un sentido similar al utilizado en referencia a instrumentos de medición, un modelo puede tener problemas de fiabilidad y problemas de validez: en el primer caso, a partir de idénticas condiciones iniciales, se obtienen resultados diferentes generados tras múltiples ejecuciones; en el segundo caso, a partir de condiciones iniciales que representan condiciones reales o empíricas bien conocidas, se obtienen resultados simulados diferentes a los resultados reales o empíricos conocidos. Antes de pasar a analizar los datos de un modelo de simulación en términos de validez es preciso verificarlo en términos de fiabilidad, esto es, la “calidad interna” del modelo: ¿El modelo de simulación realmente se comporta tal y como se pretendía al implementar el sistema social? ¿Los agentes actúan según las reglas procedentes en cada momento, según la situación en que se encuentran? ¿Las reglas de comportamiento, por separado, realmente producen los efectos que se esperaba de ellas cuando se implementaron y codificaron a partir de las hipótesis? ¿Se resuelven correctamente las situaciones de concurrencia de normas alternativas? ¿Los resultados de múltiples ejecuciones de la simulación proporcionan resultados caóticos, o pueden reconocerse patrones de equilibrio -estático, o cíclico-, de tendencias asintóticas o de agrupaciones cualitativamente similares? ¿Si seguimos individualmente a algunos agentes, verificando a través del tiempo, ocurren del modo esperado las interacciones con otros agentes?
La dificultad intrínseca de conseguir programación informática libre de errores aumenta en gran medida en el contexto de los modelos de simulación social pues un resultado inesperado puede ser generado por emergencia de comportamiento agregado de los agentes y sus interacciones tanto como por un error de programación; además, la naturaleza “distribuida” de la dinámica social, modelizada en las simulaciones sociales, dificulta la detección de los errores de programación (Axtell & Epstein, 1994: 31). Si el modelo de simulación incorpora reglas no deterministas, basadas en motores de generación de azar, obviamente cada simulación debería proporcionar resultados diferentes, pero esto forma parte de la implementación y por tanto no afecta a la evaluación de fiabilidad del modelo.
La fase de verificación es larga y compleja, y con frecuencia implicará modificaciones en el código que llevarán a nuevas pruebas de verificación. No existe una metodología consensuada para obtener una verificación de la fiabilidad para cualquier modelo de simulación multi-agente, pero pueden reconocerse algunas indicaciones (Ramanath & Gilbert, 2004), comunes entre la comunidad de practicantes de simulación social, para tratar de eliminar los errores de codificación (bugs):
- La primeras simulaciones de un modelo llevan a la detección de los errores fácilmente observables, ya que el resultado es que el sistema “se cuelga” o funciona de forma obviamente anómala. A partir de este momento, la reimplementación del código lleva a una distribución exponencial negativa de los errores donde es difícil alcanzar el cero absoluto, incluso en el caso de simulaciones publicadas (Edmons & Hales, 2003; Galán & Izquierdo, 2005; Rouchier, 2003).
- Conviene codificar de forma cuidadosa y paciente, sin buscar atajos para conseguir rápidamente un modelo funcional sino, por el contrario, implementar detalladamente cada hipótesis y mecanismo usando nombres de variables y procedimientos comprensibles.
- Conviene incorporar numerosos monitores y gráficos de estado. La depuración requiere información sobre los valores intermedios y no sólo sobre los resultados finales. Igualmente, conviene añadir controles automáticos (assertions) que avisen en caso de que se alcancen valores fuera de rango, o situaciones imposibles en el sistema. Estos dispositivos ralentizan considerablemente la ejecución de la simulación durante esta fase, pero se pueden desactivar para el modelo final a validar implementando un conmutador de depuración que establezca el tipo de simulación: depuración (debugging) o ejecución (run).
- Conviene ejecutar y observar los resultados de la simulación paso a paso, esto es, momento a momento de tiempo (simulado) o incluso línea a línea de código ejecutable. Afortunadamente, la mayor parte de los entornos de programación de simulaciones sociales facilitan está tarea con herramientas específicas.
- Conviene modificar una a una condiciones iniciales de la simulación para detectar si se producen resultados con elevada desviación del comportamiento observado, mientras se examinan cuidadosamente las variables de estado interno de agentes seleccionados, en momentos de tiempo concretos, para poder verificar su comportamiento individual.[16]
- Conviene documentar el código, incorporando comentarios y mantenerlos actualizados, encabezando cada bloque de código significativo con descripciones humanamente comprensibles -a nivel conceptual- sobre cual es su objetivo y cómo lo realiza. Se recomienda escribir un tercio más de lineas de comentarios que de lineas de código ejecutable, dirigidos a un público que puede saber cómo programar pero ignorar la lógica del modelo concreto.
- Es recomendable utilizar la técnica UT (Unit Testing), mediante la cual se programa mediante pequeñas porciones, o unidades, de código relativamente autocontenido y antes de continuar programando realizar la validación de fiabilidad de la unidad previa utilizando un juego de datos de entrada y datos esperados de salida, diseñados para contrastar el correcto funcionamiento de cada unidad. Esta contrastación es llevada acabo automáticamente, en el momento de la ejecución, por una porción de código que verifica cada vez todas las unidades anteriores y sus posibles interacciones.
- Conviene contrastar los resultados del modelo completo mediante “escenarios conocidos”, esto es, inicializando la simulación con parámetros correspondientes a datos conocidos y utilizando contrastes de ajuste entre la distribución de resultados simulada y la conocida. Esto no siempre es posible, ni asegura la fiabilidad del modelo, pero puede ser un indicador de necesidad de depuración en caso de obtener resultados absolutamente dispares.
- Conviene utilizar contrastes extremos, estableciendo los parámetros iniciales del modelo en los valores extremos para una (edge testing) o diversas variables a la vez (corner testing) mientras se estudia el comportamiento del sistema simulado en tales condiciones extremas. En general, explorar sistemáticamente el espacio de valores de los parámetros iniciales es una buena estrategia para detectar errores de fiabilidad.
7. Analizar la simulación y validar su calidad externa
La fase anterior -verificación de fiabilidad- corresponde a la evaluación del modelo computacional en cuanto correcta implementación informática de un sistema de hipótesis generativas que modeliza el fenómeno a estudiar. Tal evaluación hace referencia al modelo entendido como implementación, y no al modelo entendido como sistema válido de hipótesis explicativas.[17] Esta segunda evaluación, referida a la “calidad externa”, es el objetivo de la fase de análisis y validación.[18] Las cuestiones relevantes son: ¿Cómo cambian los datos finales con diferentes configuraciones iniciales? ¿Esas diferencias observadas tienen significado o explicación a partir de las hipótesis teóricas implementadas en el modelo? ¿Cuantas ejecuciones distintas, con idéntica configuración inicial, son necesarias para conseguir resultados “estables” y significativos? ¿Si se introduce “ruido” o aleatoriedad en el modelo cual es su impacto sobre los resultados finales? ¿Cuanto “tiempo” (simulado) es preciso ejecutar el modelo hasta conseguir capturar el conjunto del comportamiento esperado y considerar simulado el fenómeno? ¿Los resultados obtenidos al cabo del “tiempo” son estables o inestables/cíclicos/caóticos en ese periodo de tiempo, o en otro periodo mayor?
No existe una forma consensuada de validar un modelo de simulación, aunque cabe considerar que si se usa el procedimiento aquí expuesto es muy probable que el modelo, al alcanzar esta etapa del proceso, sea mucho mejor que otro que se haya construido improvisando una amalgama de código desestructurado que reproduce aproximadamente los resultados esperados (quick&dirty coding). Por otro lado, diferentes tipos de modelos requeriran de diferentes aproximaciones al problema de la validación. Axtell & Epstein (1994) ofrecen una posible clasificación de modelos de simulación según niveles de validación:
- El nivel 0 corresponde a modelos que son meras caricaturas de la realidad social, a la que representan mediante dispositivos gráficos como por ejemplo la visualización del movimiento de los agentes.
- El nivel 1 corresponde a modelos que se ajustan cualitativamente a los macro-estados de la realidad social simulada, como por ejemplo los que muestran la distribución de frecuencias de atributos o características de la población virtual.
- El nivel 2 corresponde a modelos con ajustes cuantitativos respecto a macro-estados empíricamente observables, como los que puedan ofrecer técnicas de estimación estadística.
- Finalmente, el nivel 3 corresponde a modelos que permiten mostrar ajustes cuantitativos con micro-estados, como los que ofrecen la posibilidad de realizar comparaciones y análisis longitudinales de las poblaciones virtuales y empíricas.
Hay que destacar que incluso la excelencia del modelo en el sentido de ajuste a los datos empíricos disponibles no asegura la posibilidad de validación satisfactoria, puesto que 1) los datos empíricos no siempre están disponibles en el formato requerido, y 2) aún en caso que lo estuvieran, y nos encontráramos en el nivel 3, subsiste el problema irresuelto de la identificación o sobredeterminación[19], esto es, existe la posibilidad de obtener resultados similares a partir de 2a) diferentes especificaciones del modelo y de 2b) diferentes configuraciones iniciales. El segundo caso (2b) no atenta contra la validez sino que, por el contrario, la refuerza y es el fundamento del llamado análisis de sensibilidad. El primer caso (2a) puede hacer referencia a implementaciones del mismo modelo en lenguajes de programación diferentes, lo que tiene un efecto positivo similar a (2b) sobre la validez, o puede hacer referencia a modelos fundamentalmente diferentes en cuanto a la definición de los agentes, reglas/mecanismos y entornos implicados, en cuyo caso se presenta en toda crudeza la problemática de la sobredeterminación. Sin embargo, no puede considerarse este un argumento en contra del uso de modelos de simulación en investigación social puesto que se trata de un problema generalizado de método científico.
Por su parte, Boero & Squazzoni (2005), ofrecen su propia tipología de modelos de simulación social, asociada a diferentes técnicas recomendadas para la validación de los mismos: “modelos abstractos”, “modelos de rango medio” y “modelos facsímil”. Los “modelos abstractos” pretenden formalizar y estudiar teorías sobre procesos o mecanismos sociales generales y básicos, esto es, que se pueden encontrarse en amplias áreas de la vida social. Tales modelos no representan ningún caso empírico en concreto y deben ser entendidos más bien como ejemplos de investigación teórica pura. Por consiguiente se prescribe para estos el uso de técnicas y criterios propios de la validación de teorías generales: que se basen en reglas de comportamiento individual plausibles y realistas, que generen patrones de resultados emergentes esperados e interpretables, y que sean capaces de generar teorías “de rango medio” más específicas. En cuanto al segundo criterio mencionado, la técnica adecuada es el denominado “análisis de sensibilidad”, consistente en estudiar el efecto sobre los resultados agregados de variar sistemáticamente los parámetros iniciales del modelo (explorando el espacio multidimensional de parámetros, bien sea en su totalidad de forma continua, bien sea discretamente para puntos teóricamente relevantes). Una de las consecuencias de adaptar modelos abstractos a dominios específicos suele ser el descubrimiento de la relevancia de determinados factores, que tal vez hasta el momento no había destacado el trabajo teórico.[20]
Los “modelos de rango medio” pretender describir las características de un fenómenos social de una forma suficientemente genérica como para que sea posible la aplicación de sus resultados a diversas instancias reales o casos de tal fenómeno. En tal caso se prescribe el uso de técnicas y criterios propios de la validación de teorías intermedias: el reconocimiento de patrones de similaridad de naturaleza cualitativa, esto implica unas dinámicas de comportamiento similares en el tiempo (análisis de trayectorias de eventos) y unos resultados agregados similares a los empíricamente observados. En ambos casos la similaridad debe entenderse como ajuste matemático de las curvas correspondientes de distribución estadística, pero tan sólo en cuanto a las formas generales de las curvas (Moss, 2002). Otra técnica de validación es el estudio de “historias alternativas”, generadas mediante modificaciones selectivas en las condiciones iniciales de un modelo que replica cualitativamente el desarrollo de un conjunto de casos empíricos, y que resultan consistentes con los fundamentos causales explicativos de los hechos estudiados.[21]
Los “modelos facsímil”, finalmente, pretenden representar con el máximo detalle un fenómeno empírico e histórico concreto con datos disponibles.[22] En estos casos, si los resultados de la simulación son validados mediante contrastación con los registros empíricos no sólo se consigue evaluar la calidad externa del modelo, esto es, del sistema de hipótesis implementado, sino que permiten considerarlo un “sistema experto” con capacidad para realizar predicciones futuras. La evaluación del ajuste entre los datos generados y los disponibles, para estos modelos, se rige por las mismos criterios y técnicas que los correspondientes a la metodología experimental u observacional: cálculo de indicadores agregados de correlación, como por ejemplo R² (coeficiente de determinación para modelos de regresión lineal) o V de Cramer (coeficiente de asociación para tablas de contingencia). En definitiva, la fase de validación implica diversas técnicas dependiendo del tipo de modelo, y a pesar del aún escaso desarrollo de la simulación social, no siempre resulta preferible la via “simplista” de la validación teórica ante las alternativas que tienen en cuenta los aspectos más descriptivos o de calibración empírica (Edmons & Moss, 2005; Fagiolo et al., 2007; Moss, 2008). Concretamente, en el caso de modelos “facsímil” es posible analizar los datos generados por la ejecución del modelo de simulación social, considerados como resultados experimentales en condiciones controladas definidas por la inicialización o configuración inicial de la simulación. Así,
- un modelo SSMA puede entenderse como un sistema formalizado de hipótesis explicativas,
- cada configuración inicial como un diseño experimental,
- cada simulación ejecutada mediante tal modelo como un experimento, y por tanto,
- los datos generados pueden tratarse como datos experimentales a efectos de contrastación empírica del sistema de hipótesis.
Atendiendo a la naturaleza de las entidades observacionables relevantes para cada estudio, los datos generados a partir de una simulación social multi-agente pueden ser de diversos tipos:
- desde la perspectiva de las variables, una SSMA puede generar datos agregados de indicadores poblacionales, bien sea como resumen estadístico final (distribuciones) o como registros históricos de tales resúmenes (series temporales).
- desde la perspectiva de los casos, una SSMA puede generar datos del estado individual de los agentes, bien sea como estados finales clasificables (análisis factorial, análisis de clusters) o susceptibles de estudios correlacionales (regresión, asociación, etc.), bien sean registros longitudinales individuales que describen la evolución de sus estados -físicos, mentales, sociales- a lo largo del periodo de tiempo simulado (historiales cuantitativos de sucesos, historias de vida cualitativas). Estos estados pueden incluyen, en particular, los contenidos mentales de los agentes, en forma de ontologías sociales, de mapas sociales o de normas sociales.
- desde la perspectiva de las acciones sociales, una SSMA puede generar datos detallados sobre los contextos decisionales concretos en los que se han encontrado habitualmente los agentes, así como las decisiones situadas que han tomado en cada contexto.
- desde la perspectiva de las estructuras, una SSMA puede generar datos sobre las relaciones o vínculos entre agentes en forma de redes sociales (grafos), bien sea como la red final resultante, o bien como la dinámica intermedia configuradora de tales redes (grafos evolutivos).
Cada uno de estos tipos de datos generados por simulaciones sociales requieren, y disponen actualmente, de técnicas de análisis y contrastación empírica diferentes, lo que implica una diversidad de prácticas de validación para las SSMA que excede el objetivo de este texto y remite a la literatura especializada en análisis de datos.
8. Publicar los resultados y el modelo
Los entornos de simulación más avanzados ofrecen la posibilidad de utilizar herramientas de registro y exportación de datos, así como de programación de réplicas de simulación de un modelo bajo condiciones particulares. El uso de tales herramientas, en combinación con otras herramientas informáticas de análisis de datos permite concluir la fase de análisis y validación del modelo con la obtención de determinados resultados que, como resultados de cualquier proceso científico, deben hacerse públicos permitiendo su divulgación y su discusión académica. En esta fase, las cuestiones relevantes son: ¿Los resultados obtenidos permiten validar el modelo? ¿Hasta qué punto esta validación permite justificar el sistema de hipótesis que el modelo implementa en su conjunto? ¿Atendiendo a las modificaciones y ajustes introducidos en el modelo, qué hipótesis quedan verificadas y qué hipótesis quedan falsadas? ¿Qué otras modificaciones o extensiones del modelo permitirían contrastar otras hipótesis relativas al fenómeno no consideradas por el modelo? ¿Qué datos e indicadores, numéricos o visuales, permiten comunicar de forma comprensible y eficientemente los resultados obtenidos? ¿Cómo se podrían incrementar la comparabilidad de los resultados y del modelo mismo entre la comunidad científica? ¿Cómo expresar mejor el sistema de hipótesis explicativas verificadas: literalmente, con diagramas, con pseudo-código o publicando el código completo? ¿Qué canales de comunicación científica son adecuados para la publicación de resultados de estudios sociales mediante SSMA?
Respecto a la publicación en sí misma, raramente se publica junto a los resultados el listado completo de código informático utilizado. En la literatura al respecto, hasta inicios de los años 2000 era habitual adjuntar algún tipo de representación del algoritmo aunque no el código completo, e incluso se han apuntado algunas razones para esta práctica (Gilbert & Terna, 2000):
- Los programadores se defienden así de posibles críticas relativas a su “estilo” de programación,
- Los programas finales, una vez usados, depurados y modificados sobre la marcha en función de los requerimientos experimentales, no resultan tan “elegantes” como para ser publicados,
- Los programas no son fácilmente “portables” entre diferentes sistemas operativos y máquinas.
La situación actual es diferente y así es cada vez más común encontrar enlaces URL al código completo del modelo, difundido bajo licencias abiertas.[23] Las razones de este cambio se pueden rastrear entre la proliferación de formatos electrónicos de publicación científica (que permiten anexar, sin problemas de espacio, todo tipo de material multimedia o código), la extensión de la conciencia y las prácticas de free-open software entre la comunidad de desarrolladores de aplicaciones informáticas, y los desarrollos hacia la interoperabilidad de los modelos, como el uso de entornos “amigables” (domain-friednly) para investigadores sociales o el uso meta-modelado con codificación final en lenguajes compatibles o “portables” entre máquinas (Java, C++). Hacia mediados de la década de 2000 se recomendaba en general la presentación de modelo utilizando diagramas de clase UML (Grimm et al., 2006) pero esta propuesta está siendo últimamente superada por la recomendación de utilizar un protocolo independiente del modo concreto en que los modelos son implementados; UML está demasiado ligado a la aproximación basada en agentes y a la programación orientada-a-objetos como para permitir la suficiente apertura y flexibilidad.
Así, en 2006 un numeroso equipo de investigadores del dominio de los sistemas socio-ecológicos proponen el protocolo ODD (Overview, Design concepts and Details) para estandarizar la publicación de descripciones de modelos basados en agentes, que recientemente ha sido revisado y ampliado (Grimm et al., 2010). Disponer de un protocolo normalizado promueve la formulación rigurosa de los modelos, facilita las revisiones y comparaciones entre modelos.[24]
Protocolo ODD: descripción normalizada de modelos de simulación basados en agentes.
- PROPÓSITO: ¿Cual es el propósito del modelo? ¿Con qué objetivo se ha desarrollado? ¿Para qué se va a utilizar?
- ENTIDADES, VARIABLES DE ESTADO Y ESCALAS: ¿Qué tipo de entidades conforman el modelo (agentes/individuos, unidades espaciales, medioambiente, colectividades)? ¿Qué variables de estado o atributos internos caracterizan a tales entidades, y en qué unidades se expresaran? ¿Cual es la extensión espacial y temporal del modelo, y con qué nivel de precisión se simulará?
- SUMARIO DEL PROCESO Y SU PLANIFICACIÓN (scheduling): ¿Qué entidad hace qué? ¿En qué orden se ejecutan los diferentes procesos? ¿En qué orden ejecutan las entidades en mismo proceso? ¿Cómo se modeliza el tiempo, mediante saltos discretos o como un continuo temporal en el que suceden tanto procesos continuos como sucesos discretos? [25]
- CONCEPTOS DE DISEÑO (Grimm & Railsback, 2005: cap. 5): No resultan bien descritos mediante dispositivos clásicos como ecuaciones diferenciales o gráficos de flujo, pero son fundamentales para interpretar los resultados de la simulación y por tanto se deberían explicitar como decisiones de diseño importantes que deben comunicarse conscientemente a los eventuales lectores.
4.1. Principios fundamentales: ¿Qué conceptos, teorías, hipótesis o estrategias de modelado subyacen al diseños del modelo? ¿Qué relación guardan estas asunciones con el propósito del estudio? ¿Cómo se tienen en cuenta en la modelización? ¿Se utilizan en el nivel de los submodelos (como hipótesis microfundamentales) o en el nivel del sistema (como teorías macrodinámicas)? ¿Proporcionará el modelo indicios respecto a estos principios fundamentales, como por ejemplo su alcance, su utilidad en escenarios reales, su validación o indicaciones para su modificación? ¿Utiliza el modelo teorías consolidadas o novedosas?
4.2. Emergencia: ¿Qué resultados son modelados como resultados emergente de rasgos adaptativos o de comportamiento de los individuos? ¿Que resultados del modelo se espera que varíen de forma compleja y tal vez imprevisible ante un cambio de las características particulares de individuos o entorno? ¿Qué resultados del modelo que están ya impuestos por las reglas y por tanto dependen menos de los comportamientos de los individuos?
4.3. Adaptación: ¿Qué rasgos adaptativos tienen los individuos? ¿Qué reglas tienen para tomar decisiones o modificar su comportamiento en respuesta a cambios en sí mismo o en el entrono? ¿Estos rasgos intentan incrementar algún tipo de indicador de éxito individual relacionado con sus objetivos (p.e., “desplazate a la posición que disponga de una productividad mayor”, asumiendo que productividad es un indicador de éxito)? ¿O simplemente los individuos reproducen ciertos comportamientos que se asumen implícitamente como conducentes al éxito o la adaptación (p.e., “desplazate hacia la derecha un 70% del tiempo”)?
4.4. Objetivos: ¿Qué objetivos persiguen los individuos mediante los procesos de adaptación que rigen sus comportamientos? ¿Cómo se pueden medir tales objetivos, así como su grado de cumplimiento? ¿Qué criterios usan los agentes individuales para evaluar alternativas cuando tienen que tomar decisiones?.
4.5. Aprendizaje: ¿Cambian los rasgos adaptativos a lo largo del tiempo como consecuencia de la experiencia? ¿Cómo se dan tales cambios? ¿Se trata de cambios conscientes, incluso planificados, o son simplemente respuestas a un entorno en evolución?¿Se dan procesos de co-evolución por influencia mutua entre características individuales y del entorno?
4.6. Predicción: Si es es caso, ¿cómo predice un agente las condiciones futuras que experimentará? ¿Cómo influyen tales predicciones sobre los procesos de adaptación y de aprendizaje? ¿Qué elementos, propios y del entorno, utiliza un agente individual para realizar sus predicciones? ¿Qué modelos internos (razonamiento) utilizan los agentes para estimar sus condiciones futuras? ¿Qué modelos utilizan para estimar las consecuencias futuras de sus comportamientos? ¿Qué supuestos tácitos implican tales modelos de razonamiento y racionalidad?
4.7. Percepción: ¿Qué variables de estado, internas o del entorno, se asume que perciben los agentes? ¿Qué modelo de medida usan los agentes para tal percepción? ¿Qué otros agentes o entidades son percibidas, y en concreto mediante qué atributos? ¿Mantienen los agentes una memoria o mapa a largo plazo de sus percepciones? ¿Cual es el alcance de las señales que un agente puede percibir, local o global? ¿Si la percepción es a través de una red social, su estructura es impuesta o emergente de la simulación? ¿Los mecanismos mediante los que los agentes obtienen información están modelizados explícitamente, o se asumen como dados?
4.8. Interacción: ¿Qué tipos de interacciones se asumen como relevantes entre los agentes? ¿Se trata de interacciones directas, en las que los encuentros entre agentes influyen sobre los mismos? ¿Hay interacciones indirectas, como en caso de competir por un recurso intermedio? ¿Si las interacciones implican comunicación, cómo se han modelizado tales procesos comunicativos?
4.9. Aleatoriedad: ¿Qué procesos se han modelado asumiendo que son, total o parcialmente, aleatorios? ¿Se utiliza la aleatoriedad para generar variabilidad en procesos para los que no se considera importante modelizar sus causas? ¿Se utiliza aleatoriedad para generar sucesos o comportamientos que ocurren con una frecuencia específica conocida?
4.10. Colectivos: ¿Los individuos forman o pertenencen a agregaciones que influyen y son influidas por los mismos individuos? ¿Cómo se representan tales colectividades? ¿Tales colectivos son una propiedad emergente del comportamiento de los individuos? ¿Son los colectivos simplemente definiciones del modelador, es decir, conjuntos de entidades con sus propios atributos y comportamientos?
4.11. Observación: ¿Qué datos se generan y recopilan a partir de la simulación a efectos de análisis? ¿Cómo son recopilados tales datos, y en qué momento? ¿Se utiliza la totalidad de los datos generados, o sólo una muestra a imitación de lo que sucede habitualmente en un estudio empírico? - INICIALIZACIÓN: Resulta imposible realizar replicas de una simulación sin conocer las condiciones de inicialización del modelo. ¿Cual es el estado inicial del modelo, esto es, en el momento t=0 de la ejecuciónde la simulación? ¿Cuantas entidades forman la sociedad virtual inicialmente, y qué valores, exactos o como distribución aleatoria, tienen las variables de estado de las entidades? ¿Es siempre idéntica o puede variar entre diferentes ejecuciones de la simulación? ¿La inicialización corresponde a un estado del mundo real, esto es, está empíricamente calibrada (data-driven), o los valores son arbitrarios? ¿Si se trata de una situación inicial experimental, cómo corresponden los valores arbitrarios a hipótesis concretas a contrastar?.
- DATOS DE ENTRADA: No hace referencia a los valores paramétricos iniciales de la simulación, sino a registros de procesos ambientales que pueden influir (drive) sobre la simulación a lo largo de su ejecución sin que sean a su vez resultado del modelo como, por ejemplo, ciclos climáticos. ¿Utiliza el modelo datos de fuentes externas (ficheros de datos, u otros modelos) para representar procesos que varían en el tiempo durante la simulación?
- SUBMODELOS: ¿Qué modelos representan, con detalle, los procesos listados en el apartado (3) de procesos y planificación? ¿Cuales son los parámetros, dimensiones y valores de referencia de cada modelo? ¿Qué ecuaciones o algortimos permiten representar cada modelo? ¿Cómo se han diseñado o seleccionado tales modelos? ¿De qué otros sistemas se han “extraído” o “inspirado” los modelos para su uso actual? ¿Cómo se justifica la verificación y la validez de cada modelo utilizado? ¿Qué referencias y literatura relevante se puede aportar para cada submodelo, respecto a su implementación independiente, contraste, calibración y análisis?
A pesar de que el protocolo ODD se ha diseñado para describir, a efectos de comunicación científica y publicación, la versión definitiva del modelo, en realidad pueden existir diferentes versiones anteriores del mismo debido al proceso recursivo e incremental de refinamiento en la construcción de los modelos. Igualmente, convendría añadir a las secciones propias del protocolo ODD una última sobre “Experimentos de Simulación” y “Análisis del Modelo”, en las que se describiera el plan de experimentación al que se ha sometido el modelo, la descripción e incidencias del conjunto de simulaciones realizadas, y los resultados generados por el conjunto: modelo, plan de explotación, simulaciones, análisis. Estas consideraciones quedan, actualmente fuera del ámbito del protocolo descriptivo ODD, pero forman parte fundamental de los resultados publicables, a efectos de posible replicabilidad por parte de la comunidad científica.
Para concluir este apartado dedicado a las etapas del protocolo de investigación social mediante simulaciones informáticas parece conveniente añadir algunas consideraciones finales sobre criterios que pueden guiar la mencionada recursividad y refinamiento a lo largo del proceso. Cuando se plantea la realización de un modelo formal, es usual defender y practicar el denominado principio KISS (“keep it simple, stupid!”) que prescribe comenzar con un representación simple, idealizada e incluso irrealista del fenómeno a modelar, pero que funcione efectivamente, para ir introduciendo posteriores modificaciones y complicaciones que avancen incrementalmente hacia el objetivo de reproducir el sistema social que se desea investigar (Axelrod, 1997). Por ejemplo, Antunes (2007) propone una secuencia posible de “profundización incremental” de un concepto concreto que se estima relevante para explorar la dinámica del fenómeno social considerado. Sea a un atributo propio de agentes participantes en el modelo (por ejemplo, sus ingresos, su honestidad, o su opinión respecto a las cargas fiscales que recibe), se podría comenzar por considerar a constante, posteriormente modificar el modelo para considerar a variable y asignarle alguna distribución probabilística típica, posteriormente asignarle una distribución probabilística calibrada a partir de observación empírica, posteriormente sustituir esta distribución por un mecanismo externo causal que determine a, posteriormente sustituir ese mecanismo por un mecanismo evolutivo y adaptativo que seleccione el valor de a, posteriormente sustituir completamente la variable a por un mecanismo reactivo que genere el valor de a según la situación, y así sucesivamente aumentar la complejidad y realismo de modelo. Esta estrategia incremental tiene dos beneficios principales: técnicamente facilita la construcción de los modelos informáticos, y teóricamente obliga a especificar los componentes y dinámicas de los fenómenos sociales de una forma mucho más detallada y formal de lo que acostumbra a ser la práctica sociológica (Arroyo & Hassan, 2007: 155).
6. Construcción de simulaciones sociales multi-agente (SSMA): Herramientas.
Construir una SSMA es una tarea larga y compleja si se utilizan técnicas de programación básicas sin ningún tipo de ayuda. Escribir el código fuente para simular la dinámica de la sociedad artificial implementada implica especificar y programar cada comportamiento de cada elemento, así como cada posible interacción entre elementos, los resultados de las interacciones y las representaciones de todo ello. Existen al menos cuatro aproximaciones, de complejidad incremental en cuanto a su tecnología computacional, para conseguir construir un modelo de simulación social: 1) programar todo el código directamente, 2) utilizar “librerías” de código prefabricado para escribir el propio código, 3) utilizar “plataformas” o entornos integrados, con ayudas para la programación sin necesidad de escribir directamente el código, y 4) herramientas de meta-modelado que generan automáticamente el código ejecutable a partir de una especificación formal abstracta y detallada del modelo. Las cuatro primeras opciones implican necesariamente conocimientos de programación, mientras que la última aproximación permite la modelización directa por parte de expertos en el campo social de referencia.
En términos de programación informática, en los últimos años se ha desarrollado bastante la ingeniería del software orientada a agentes con lo que han ido apareciendo diversas “plataformas” genéricas para generar modelos de simulación multi-agente.[26] Sin embargo, los sistemas multi-agente propios del dominio de la informática y de la industria típicamente utilizan un numero reducido de agentes “complejos” (con elevados requerimientos computacionales en cuanto a procesamiento de datos), mientras que en el caso particular de la SSMA, contrariamente, se requiere habitualmente un número muy elevado de agentes relativamente “simples”. Por ello las plataformas de programación genéricas, enfocadas hacia los SMA clásicos, se adaptan imperfectamente a las necesidades de la SSBA.
Además, el uso de las primeras herramientas mencionadas supone que la programación del modelo es implementada por un experto ingeniero de software, según las indicaciones del experto investigador social que posee el adecuado conocimiento del modelo sociológico correspondiente a la sociedad artificial que se intenta construir. Según esta distribución del trabajo se perfilan tres vías distintas para el desarrollo de SSMA:
- Las primeras experiencias de simulación social, con científicos sociales “invitados” a aportar problemas susceptibles de ser modelizados por ingenieros informáticos [27],
- Los investigadores sociales adquieren competencias de programación, como parte especializada de su oficio [28], o
- Se producen herramientas de software que permitan modelar y simular SSMA de modo simple y asistido, análogamente a cómo se pueden llevan a cabo hoy en día complejos análisis multivariante mediante paquetes de análisis estadístico (Repast Suite, INGENIAS, Modelling4all, y IodaProject).
Gilbert & Terna (2000) expresaron la recomendación generalizada entre los practicantes de SSBA de usar lenguajes orientado-a-objetos para la programación de sistemas de simulación social. En tal caso, computacionalmente, los agentes serian objetos (objects) y los sucesos serian cambios temporales (time steps) activados por bucles en el programa. En esa perspectiva de programación cada “objeto” es una porción de código informático unitaria que contiene datos sobre sus atributos de estado y también reglas que gobiernan su comportamiento. Sin embargo, más allá de la similitud estructural entre la metodología de programación y la aproximación modelizadora, existen otros criterios relevantes para elegir las herramientas de programación adecuadas para construir simulaciones sociales. En una cita de su mismo trabajo: “Sólo si utilizamos programario de alta calidad seremos capaces de comunicar los detalles de nuestro modelo, permitiendo a otros académicos replicar los resultados, y evitando la dificultad inherente en la modificación de código pobremente escrito” (Gilbert & Terna, 2000) se pone de manifiesto que la tensión fundamental en relación a este punto no se da entre técnicas más o menos similares a la aproximación SSBA, sino entre formas de programación que promuevan los auténticos objetivos de la investigación social, esto es, la comunicación del formalismo que representa el modelo y la capacidad de modificación, adaptación y reutilización del código. En esta linea, hay que destacar que las prácticas y las tecnologías desarrolladas al respecto en el primer decenio del siglo XXI se han orientado efectivamente hacia el objetivo fundamental de facilitar la comunicación, la replicación y la reutilización de modelos y sus componentes por parte de la comunidad científica social.[29] Esto deja tan sólo dos vías alternativas: 1) la utilización de herramientas de alto-nivel, como parte de la formación especializada metodológica por parte de científicos sociales, y 2) el meta-modelado, como solución al alcance de expertos sociales no-programadores. La programación de SSBA mediante herramientas de alto-nivel permite concentrarse en la implementación de las características o atributos de los agentes, y de las reglas de producción correspondientes a los mecanismos físicos, psicológicos y sociales propios del fenómeno social que se intente simular, sin preocuparse especialmente por detalles de implementación o programación. Estas herramientas se encargan de resolver, de una forma cada vez más transparente para el programador, los problemas de gestión de la memoria de trabajo y de simulación de los pasos temporales. Igualmente, cada vez más se han desarrollado interfases encargadas de la representación gráfica de sucesos puntuales y de resultados agregados sin necesidad de programación específica. Sin embargo, aún se dirigen a un público experto en programación al que facilitan considerablemente la tarea de construir SSMA. Por el contrario, la perspectiva del meta-modelado dirige sus esfuerzos hacia un público lego en programación informática, capacitándolo como usuario de herramientas de generación de modelos.
A continuación se presentan brevemente algunas de las principales herramientas, de alto-nivel y de meta-modelado, disponibles para realizar modelos de simulación computacional de utilidad en investigaciones sociales. Abundante literatura evalúa las alternativas disponibles en cada momento (p.e., Axtell, 2006), en cuanto a su dificultad y rendimiento. El listado siguiente pretende ofrecer una guía para la evaluación de distintas herramientas según dos criterios: a) el uso consolidado entre la comunidad de modelizadores sociales y b) la sencillez de aprendizaje y utilización. Todas ellas pertenecen a alguno de los dos paradigmas de programación de SSMA con un desarrollo futuro más prometedor (Railsback et al., 2006) “library and framework paradigm”, en el que se dispone de un conjunto de conceptos estandarizados para el diseño de un sistema multi-agente (framework) junto con un conjunto de aplicaciones informáticas que implementan tales conceptos y proporcionan las herramientas de simulación (library). Se requieren conocimientos de programación informática, especialmente en Java, para poder combinar y usar el conjunto de libraries para construir un modelo personalizado. Forman parte de este paradigma de computación las plataformas más antiguas y habitualmente utilizadas, como SWARM, RePast, MASON, o 2) “Logo-like”, en el que se dispone de un lenguaje simplificado de alto-nivel [30] para construir sistemas multi-agente y modelizar los fenómenos deseados. StarLogo (y su actual sucesor, Netlogo) son ejemplos “directos” de esta aproximación, pero cualquier otro entorno de programación se acerca al paradigma “Logo” si ofrece herramientas de programación visual o de meta-modelado para desarrollar el modelo sin conocer el lenguaje de programación final (Repast Suite, INGENIAS, Modelling4all, o IodaProject).
SWARM <https://www.swarm.org>: Es una plataforma de construcción de modelos informáticos basada en el lenguaje de programación “Objective C”, que se comenzó a desarrollar antes de que Java se convirtiera en el lenguaje maduro y ampliamente extendido que es hoy en día. Incorpora un marco conceptual, desarrollado desde mediando de la década de 1990 en el Santa Fe Institute <https://www.santafe.edu/> para diseñar, describir y llevar a cabo experimentos virtuales sobre simulaciones basados en agentes, así como diversas aplicaciones que proporcionan numerosas herramientas para implementar modelos, y una extensa comunidad de usuarios y desarrolladores que comparten ideas, experiencias y ejemplos de programación. A lo largo de los años se ha consolidado como una plataforma potente y adecuada para desarrollar modelos de simulación social de fenómenos complejos, aunque su dificultad de aprendizaje para no expertos en programación ha llevado a desarrollar otras herramientas y accesorios de asistencia para facilitar la construcción de modelos sociales en pseudo-codigo de alto nivel sin necesidad de programar en detalle, por ejemplo MAML (Multi-Agent Modeling Language <https://www.maml.hu/>, REPAST o MASON).
MASON <https://cs.gmu.edu/~eclab/projects/mason/>: Originariamente se creó como una alternativa más rápida y reducida a REPAST. Es un conjunto de bibliotecas escritas en lenguaje Java, especializadas en la construcción de modelos de simulación altamente eficientes para sistemas de acontecimientos discretos con gran cantidad de agentes. Se trata de una iniciativa conjunta entre el Laboratorio de Computación Evolucinaria (ECLAb) y el Centro de Complejidad Social, de la Universidad George Mason (USA). Actualmente parece la herramienta menos madura de entre todas las disponibles (Railsback et al., 2006) y su desarrollo parece concentrarse más en la eficiencia de la ejecución que en las facilidades de modelización y análisis.
CORMAS <https://cormas.cirad.fr>: Originariamente se creó como asistente para el desarrollo de simulaciones de forma cooperativa con los propios interesados, dentro del dominio específico de la cooperación al desarrollo social y medioambiental a sociedades en desarrollo. Es una plataforma de simulación basada en el entorno VisualWorks que permite desarrollar modelos multi-agente mediante el lenguage de programación orientado-a-objetos SmallTalk. Esta especializado en la modelización de gestión de recursos naturales renovables teniendo en cuenta las dinámicas de interacción entre los agentes implicados y ha sido desrrollada por el equipo “Gestion des ressources renouvelables et environnement” (GREEN) del “Centre de coopération internationale en recherche agronomique pour le développement” (CIRAD).
REPAST <https://repast.sourceforge.net/> : Originariamente se creó como una versión de SWARM que usaba lenguaje Java. Es un entorno de software libre y gratuito para crear simulaciones basadas en agentes, propias del domino de las Ciencias Sociales y que usa el lenguaje Java (en sus versiones Suite) o C++ (en sus versiones “High Performance Computing”, desde diciembre de 2010). Permite desarrollar modelos utilizando diversas estrategias: mediante su propio dialecto de Logo (ReLogo), importando modelos de Netlogo, gráficamente (diagramas de fujo), mediante programación dinámica (Groovy) o directamente en Java. En las últimas versiones el desarrollo se orienta hacia la facilidad de modelado por parte de usuarios no expertos en programación, avanzando las versiones Suite en la práctica hacia un entorno de meta-modelado. También incorpora, como Netlogo, una herramienta de automatización de simulaciones.
NETLOGO <https://ccl.northwestern.edu/netlogo/>): Originariamente se creó como una herramienta educativa para niveles básicos, como ampliación de StarLogo (que a su vez ampliaba el lenguaje LOGO original). Es un entorno integrado de programación gratuito, dedicado específicamente a la modelización y simulación de fenómenos naturales y sociales como sistemas complejos que evolucionan con el tiempo y constituidos por centenares o miles de “agentes” independientes que trabajan de forma concurrente. Dispone de una extensa documentación, tutoriales para su aprendizaje y una biblioteca de modelos referentes a diversas disciplinas que pueden ser reusados y modificados, además de una amplia y creciente comunidad de usuarios. Las simulaciones generadas por Netlogo están implementadas internamente en lenguaje Java, pero no es preciso conocer Java para programar modelos Netlogo ya que se utiliza un lenguaje de programación propio, de muy alto nivel, que contiene elementos que reducen considerablemente el esfuerzo de programación y de visualización de resultados. Como características distintivas, además de un entorno “inteligente” de programación (que controla en tiempo real diversos aspectos relativos a la correcta escritura del código Netlogo), Netlogo incorpora una herramienta de automatización para la repetición de simulaciones, incluso con cambios de parámetros iniciales, y para la exportación de resultados en formato CSV (recuperables desde MS-Excel, SPSS, etc.). Puede ejecutarse en todo tipo de sistemas operativos, o incluso a través de WWW mediante un navegador. A partir de la versión 5 (beta01, marzo 2011) incluye el interfaz en castellano.
MIMOSA <https://mimosa.sourceforge.net/>: “Méthodes Informatiques de MOdélisation et Simulation d'Agents” es la evolución de la plataforma CORMAS para modelizar sistemas socio-ambientales. Se trata de un entorno integrado que permite construir modelos de simulación social, ejecutarlos, visualizarlos y analizarlos. Su marco conceptual implica iniciar cualquier modelo construyendo una ontología (o vocabulario concreto) como un conjunto de categorías, atributos y relaciones propias del sistema que se pretende modelizar. A continuación se modeliza la dinámica para cada categoría y se crean los modelos concretos (instancias), se componen las condiciones para las simulaciones mediante especificación de sus parámetros, gráficos, espacios, datos y herramientas estadísticas, y se pueden ejecutar las simulaciones así diseñadas. Está basada en DEVS, se puede ejecutar sobre cualquier sistema operativo y su forma de funcionamiento es esencialmente visual. En su primera versión se puede encontrar en inglés, francés y español. Permite programar la dinámica del sistema utilizando diversos lenguajes -Java, Scheme, Jess, Python, Prolog y Smalltalk- y acercamientos -ecuaciones diferenciales, reglas, agentes-.
MODELLING4ALL <https://modelling4all.org >: Es una herramienta de meta-modelado basada en tecnologías abiertas Web 2.0 (Google Web Toolkit, AJAX y JavasScript) que permite construir, ejecutar, visualizar, analizar y compartir modelos de simulación basados en agentes. No se “ejecuta” en el propio ordenador, sino en los servidores dedicados alojados en Oxford, a través de un navegador WWW sobre cualquier sistema operativo. Su lógica se fundamenta en la construcción de modelos de simulación, por parte de expertos no-programadores, a partir de la composición del modelo mediante módulos prefabricados denominados “micro-behaviours”. Tales módulos responden a elementos específicos de dinámicas sociales y otros, y están constituidos por porciones de código informático que pueden ser modularmente acoplados; cada módulo se presenta en forma de página web. Tras la definición/construcción del modelo, que queda alojado de forma anónima en los servidores centrales, su ejecución genera una instancia de simulación completa programada en lenguaje Netlogo [31] que puede ser ejecutada 1) directamente en el navegador -como JavaApplet-, o 2) puede ser descargada para ser ejecutada localmente con Netlogo. La generación de la simulación ejecutable depende de la resolución de los conflictos de concurrencia y activación de los diversos micro-behaviours para los diferentes agentes, pero este problema es resuelto por el sistema Modelling4All de forma transparente para el modelador, que no necesita ni conocer el lenguaje Netlogo, ni programar la planificación de la ejecución. Alrededor del sitio web se constituye una comunidad de usuarios que comparten, discuten, revisan, evalúan y clasifican los diferentes modelos, micro-behaviours, tutoriales y materiales para la formación aportados. Una ventaja adicionales exclusiva de esta aproximación es la posibilidad de establecer un equipo de expertos que trabajen de forma simultánea y telemática en el desarrollo del mismo modelo.
INGENIAS <https://grasia.fdi.ucm.es/main/node/67>: Desde el año 2000, la iniciativa INGENIAS acumula la experiencia de miembros del Grupo de Agentes Software, Ingeniería y Aplicaciones de la Universidad Complutense de Madrid (GRASIA), que aplicar los conocimientos adquiridos en simulación con agentes en otros ámbitos en el desarrollo de una herramienta de meta-modelado para la simulación en ciencias sociales. El objetivo de diversos proyectos asociados a esta iniciativa (como SICOSSYS en colaboración con INSISOC) es avanzar hacia el desarrollo de aplicaciones que permitan a expertos en ciencias sociales elaborar simulaciones sin necesidad de depender de expertos en inteligencia artificial, ni de disponer de conocimientos ni habilidades específicos de programación informática. INGENIAS se ha desarrollado sobre la plataforma Repast, con Java como lenguaje de ejecución y Eclipse como entorno de programación, posee un lenguaje gráfico de modelado de agentes y un módulo de generación de código muy potente (Gómez-Sanz & Pavón, 2003). La versión básica de la plataforma INGENIAS ya incorporaba posibilidades de generación de numerosas poblaciones de agentes, además de ofrecer un cierto grado de personalización para un dominio de aplicación concreto, aunque aún no disponía de las plantillas necesarias para poder generar código adaptado a la simulación social.
IODA PROJECT <https://www.lifl.fr/SMAC/projects/ioda/>: “Interaction Oriented Design of Agent Simulations” es una metodología en desarrollo e innovadora para la construcción de modelos de simulación multiagente desarrollada por el equipo SMAC de Universite des Sciences et Technologies de Lille (Univ. Lille 1). Contrariamente al resto de las herramientas aquí revisadas IODA no se fundamenta en los agentes y sus reglas de comportamiento sino en las nociones básicas de interacción y entidad: La modelización de fenómenos se realiza a partir de la formalización de las interacciones que se llevan a cabo y definen la dinámica del sistema, en forma de “matriz de interacciones entre entidades”. La herramienta de meta-modelado “Java Environment for the Design of agent Interactions” (JEDI) demuestra cómo diseñar visualmente modelos de simulación basados en interacciones, y generar automáticamente el código informático ejecutable para la simulación; esta demostración, actualmente permite implementar sistemas sociales compuestos por un máximo de 4 tipos de agentes, meramente reactivos, sin representación de su entorno ni objetivos planificados, ubicados en un espacio bidimensional homogéneo y con periodos discretos de tiempo.
Apuntes finales
La estrategia metodológica de modelado y simulación informática es un instrumento al servicio de las prácticas de investigación social en general, y sociológica en particular. La SSMA sigue lógicas habituales a otras modalidades en procesos de investigación social, que pueden sistematizarse mediante un protocolo de fases de desarrollo, y dispone de un conjunto suficiente en constante ampliación de herramientas para la construcción de modelos sociales computacionales y la realización de simulaciones sociales.
Una de las principales razones por las que la simulación social puede interesar a un número creciente de investigadores sociales es la posibilidad de modelizar a partir de hipótesis teóricas, construyendo “laboratorios sociales virtuales” para contrastar explicaciones sin necesidad de recrear en la vida real situaciones de experimentación. Ante este planteamiento, es conveniente destacar el hecho incuestionable de que se requiere que el modelo, o “sociedad artificial”, utilizado esté ampliamente desarrollado, calibrado y validado con datos empíricos, hasta el punto de convertirse en un “sistema experto”. En tal caso se podría utilizar para introducir nuevos elementos (datos, o normas de comportamiento) y ejecutar la simulación para obtener los resultados correspondientes. Pero, como se ha expresado anteriormente, cuando un sistema simulado llega a substituir hasta cierto punto al sistema real, deja de ser “simulación” y pierde su sentido en cuanto que proceso o metodología de incremento de conocimiento. En la actualidad tales modelos no están disponibles para la mayoría de fenómenos sociales, y por lo tanto, no está disponible en tal sentido la utilidad de la simulación computerizada como “laboratorios sociales”. Sin embargo, cabe destacar en otro sentido, que un modelo de simulación suficientemente verificado y dotado de interfases avanzados humano-máquina permite ya actualmente incorporar a agentes humanos al sistema, constituyendo una prometedora plataforma para la experimentación con humanos en entornos virtuales. En este segundo sentido la SSMA puede promover el desarrollo futuro de la metodología experimental y de laboratorio en las Ciencias Sociales.
Como todo instrumento, el uso de SSMA tiene el inconveniente de requerir un proceso específico de aprendizaje. Gracias a los desarrollos recientes, y a la previsible proyección futura, de las herramientas implicadas, se puede esperar una reducción considerable del esfuerzo de aprendizaje requerido para la la adquisición de competencias para su utilización.
Como todo instrumento, el uso de SSMA genera modificaciones en las habilidades y competencias habituales de sus practicantes. Debido a sus requerimientos estrictos se puede esperar que promueva una intensificación del proceso de reflexión, análisis y formalización de los fenómenos sociales a los que se aplica: 1) por la necesidad de trabajar desde una perspectiva global y sistémica respecto al proceso social considerado como sistema a modelizar, en el contexto de otros hechos y procesos sociales que especifican los límites o entorno del sistema considerado, 2) por la mayor precisión de cualquier lenguaje informático, frente al lenguaje natural, utilizado para modelizar un sistema social, lo que impulsa el desarrollo de modelos explicativos teóricos más precisos, mejor comunicables y mejor contrastables que los habituales en Ciencias Sociales, y 3) por requerir la necesaria combinación de diversas explicaciones, teorías y datos, lo que impulsa la formulación de preguntas que quizás anteriormente no se habían planteado al considerarse propias de la atención de otras disciplinas.
Selección de recursos WWW
Asociaciones científicas: Existen actualmente tres sociedades académicas regionales dedicadas a la simulación social en general, y al modelado multi-agente de fenómenos sociales en particular. Cada una de ellas celebra conferencias anuales, y bianualmente se celebra un congreso Mundial conjunto:
- Noth American Association for Computinational Social and Organization Sciences (NAACSOS), <https://www.casos.cs.cmu.edu/naacsos/>.
- Pacific Asian Association of Agent-Based Approach in Social Systems Sciences (PAAA), <https://www.paaa-web.org/>.
- European Social Simulation Association (ESSA), <https://www.essa.eu.org/>.
Revistas: Existen diversas revistas electrónicas sobre simulación informática en las que se pueden encontrar y publicar artículos sobre simulación social:
- Journal of Artificial Societies and Social Simulation (JASSS), <https://jasss.soc.surrey.ac.uk/JASSS.html>, sólo versión electrónica, cuatro ejemplares al año, gratuita.
- Computational and Mathematical Organization Theory (CMOT), versión electrónica de pago en <https://www.springer.com/business+%26+management/business+for+professiona... de la revista de NAACSOS.
- Artificial Life Online <https://www.alife.org>, versión electrónica de la revista en papel “Artificial Life”, publicada por el Instituto Santa Fe <https://www.santafe.edu>.
Listas de correo y referencias WWW seleccionadas:
- SIMSOC es una lista de distribución por correo-e gratuita de noticias referentes a publicaciones, congresos, talleres y ofertas de trabajo de interés para especialistas en simulación social. Inscripción y la consulta de archivos disponible en <https://www.jiscmail.ac.uk/lists/simsoc.html>.
- Leigh Testfatsion mantiene un excelente sitio WWW sobre Economía Computacional especialmente dedicado a la modelización de comportamiento económico multi-agente, en <https://www2.econ.iastate.edu/tesfatsi/ace.htm>.
- El sitio WWW del “Centre for Research in Social Simulation” (CRESS), del Departamento de Sociología en la Facultad de Arts & Human Sciences de la Universidad de Surrey (UK) contiene un interesante listado de enlaces en <https://cress.soc.surrey.ac.uk/web/links>, y una página WWW <https://cress.soc.surrey.ac.uk/qasss> adjunta a la excelente introducción a la modelización multi-agente de fenómenos sociales que supone el libro “Agent-Based Models” de Nigel Gilbert (2008).
- El “Grupo de Ingeniería de Sistemas Sociales” (INSISOC) de la Universidad de Valladolid mantiene un manual de introducción a NetLogo en <https://sites.google.com/site/manualnetlogo/> y en <https://www.insisoc.org/introduccion_a_netlogo.html>. Igualmente, el “Institute for Modeling Complexity” del “Advanced Learning Center”, Mesa State College de UTEC mantiene la versión en castellano del Laboratorio de Aprendizaje de NetLogo en <https://online.sfsu.edu/~jjohnson/NetlogoTranslation/index.html>, con tutoriales y explicaciones sobre el proceso de modelado.
REFERENCIAS
Ahrweiler, P. & Gilbert, N. (eds.) (1998) Computer simulations in science and technology studies. Berlin: Springer.
Antunes, Luis; Balsa, Joao & Coelho, Helder (2007) “Tax Compliance Through MABS: The Case of Indirect Taxes”, en Neves, Santos & Machado (eds.) EPIA 2007, LNAI 4874, Berlin,Heidelberg: Springer-Verlag, 605-617.
Arroyo, Millán & Hassan, Samer (2007) “Simulación de procesos sociales basada en agentes software ”, EMPIRIA. Revista de Metodología de Ciencias Sociales 14(julio-dicembre): 139-161.
Axelrod, R. (1995) “A model of the emergence of new political actors”, en Gilbert & Conte (eds.) (1995) Artificial Societies: the Computer Simulation of Social Life. London: UCL Press.
Axelrod, R. (1997) “Advancing the art of simulation in the social sciences”, en Conte, Hegselmann & Terna, P. (eds.) Simulating Social Phenomena. LNEMS, vol. 456, Heidelberg: Springer.
Axtell, R. (2006): Platforms for Agent-Based Computational Economics. Presentation, VII Trento Summer School.
Axtell, R.L. & Epstein, J.M. (1994) “Agent Based Modeling: Understanding Our Creations”, The Bulletin of the Santa Fe Institute, Winter 1994: 28-32.
Ballot, G. & Taymaz, E. (1999) “Technological change, learning and macroeconomic co-ordination: an evolutionary model”. JASSS, Journal of Artificial Societies and Social Simulation 2(2) <https://www.soc.surrey.ac.uk/JASSS/2/2/3.html>
Boero, Riccardo & Squazzoni, Flaminio (2005). “Does Empirical Embeddedness Matter? Methodological Issues on Agent-Based Models for Analytical Social Science”. JASSS, Journal of Artificial Societies and Social Simulation 8(4)6. <https://jasss.soc.surrey.ac.uk/8/4/6.html>.
Bommel, P. & Müller, J.P. (2007) “An introduction to UML for modelling in the human and social sciences”, en Denis Phan & Frédéric Amblard (eds.) Agent-based modelling and simulation in the social and human sciences. Oxford: Bardwell Press, p. 273-294.
Brainard, William C. & Scarf, Herbert E. (2005) “Brainard and Scarf on Equilibrium Prices”. American Journal of Economics and Sociology, Blackwell Publishing, 64(1):57-83, 01.
Bratman, M.E. (1987) Intention, Plans, and Practical Reason. Cambridge, MA.: Harvard University Press.
Bunge, Mario (2004) “How Does it Work? The Search for Explanatory Mechanisms”. Philosophy of the Social Science, 34(2).
Capcarrere, M.; Sipper, M. & Tomassini, M. (1996) “Two-state, r=1 cellular automaton that classifies density”, Phys. Rev. Lett. 77: 4969.
Chattoe, E. & N. Gilbert (1997) “A simulation of adaptation mechanisms in budgetary decision making”, en Conte, Hegselmann & Terna (eds.) Simulating Social Phenomena. Berlin: Springer-Verlag, Lecture Notes in Economics and Mathematical Systems, Vol. 456., pp. 401-418.
Conte, R.; Hegselmann, R. & Terna, P. (eds.) (1997) Simulating Social Phenomena. Berlin: Springer-Verlag, Lecture Notes in Economics and Mathematical Systems, Vol. 456.
Davis, M. D. (1971) Introducción a la teoría de juegos. Madrid: Alianza Editorial.
Dean, J.S.; Gumerman, G.J.; Epstein, J.M.; Axtell, R.L.; Swedlund, A.C.; Parker, M.T. & McCarroll, S. (2000) “Understanding Anasazi Culture Change Through Agent Based Modeling in Dynamics”, en Kohler & Gumerman (eds.) (2000) Human and Primate Societies: Agent Based Modeling of Social and Spatial Processes. New York & London: Santa Fe Institute / Oxford University Press.
Demeulenaere, Pierre (ed.) (2011) Analytical Sociology and Social Mechanisms, Cambridge: Cambridge University Press.
Díez, J.A. (1997) “Las concepciones semánticas de las teorias científicas”. Madrid: UNED, ÉNDOXA, Series filosóficas 8: 41-91.
Díez, J.A. & Ulises Moulines, C. (2008) Fundamentos de filosofía de la ciencia. Barcelona: Ariel, 3a. ed.
Edmonds, Bruce & Moss, Scott (2005) “From KISS to KIDS - An 'Anti-Simplistic' Modelling Approach”, en Davidsson, Logan & Takadama (Eds.) Multi-Agent and Multi-Agent-Based Simulation. LNAI, Berlin/Heidelberg: Springer.
Edmons, B. & Hales, D. (2003) “Replication, Replication and Replication: Some Hard Lessons from Model Alignment”. JASSS, Journal of Artificial Societies and Social Simulation 6(4)11. <https://jasss.soc.surrey.ac.uk/6/4/11.html>
Fagiolo, G.; Windrum, P. & Moneta, A. (2007) “A Critical Guide to Empirical Validation of Agent-Based Economics Models: Methodologies, Procedures, and Open Problems”. Computational Economics, 30(3).
Ferber, J. (1999) Multi-Agent Systems. An Introduction to Distributed Artificial Intelligence. London: Addison Wesley.
Flach, P.A. & Kakas, Antonis C. (Eds.) (2000) Abduction and Induction: Essays on their Relation and Integration. Dordrecht,Boston: Kluwer Academic Publishers, Applied Logic Series, Vol. 18.
Fonseca, Pau (2009) “SDL, a graphical language useful to describe social simulation models”, en Francisco J. Miguel (ed.) Social Simulation and Artificial Societies Analysis. CEUR Worshop Proceedings 442(4). <https://ceur-ws.org/Vol-442/p4_Fonseca.pdf>
Galán, J.M. & Izquierdo, L.R. (2005) “Appearances Can Be Deceiving: Lessons Learned Re-Implementing Axelrod's 'Evolutionary Approach to Norms''. JASSS, Journal of Artificial Societies and Social Simulation 8(3)2. <https://jasss.soc.surrey.ac.uk/8/3/2.html>.
Gardner, M. (1970) “Mathematical Games: The fantastic combinations of John H. Conway’s new solitaire game Life”, Scientific American 223: 120-123.
Giddens, Anthony (1984) La constitución de la sociedad: bases para la teoría de la estructuración. Buenos Aires: Amorrortu Editores, 2006.
Gilbert, N. (1995) “Emergence in social simulation”, en Gilbert & Conte (ed.) Artificial Societies: the computer simulation of social life. London: UCL Press, pp. 144-156.
Gilbert, N. & Conte, R. (eds.) (1995) Artificial Societies: the Computer Simulation of Social Life. London: UCL Press.
Gilbert, N. & Troitzsch, K.G. (2006): Simulación para las ciencias sociales. Madrid: McGraw Hill.
Gilbert, Nigel (2008) Agent-Based Models. Thousand Oaks, CA: Sage Publications, Quantitative Applications in the Social Sciences, 153.
Gilbert, Nigel & Terna, Pietro (2000) “How to build and use agent-based models in social science”. Mind and Society: Cognitive Studies in Economics and Social Sciences 1(1): 57-72.
Gómez-sanz, J. & Pavón, J. (2003) “Agent oriented software engineering with INGENIAS”, en 3rd International Central and Eastern European Conference on MultiAgent Systems (CEEMAS 2003), June 16-18, 2003, Prague, Czech Republic.
Grimm, V. & Railsback, S. F. (2005) Individual-Based Modeling and Ecology. Princeton: Princeton University Press.
Grimm, V.; Berger, U.; Bastiansen, F.; Eliassen, S.; Ginot, V.; Giske, J.; Goss-Custard, J.; Grand, T.; Heinz, S.; Huse, G.; Huth, A.; Jepsen, J. U.; Jørgensen, C.; Mooij, W. M.; Müller, B.; Pe'er, G.; Piou, C.; Railsback, S. F.; Robbins, A. M.; Robbins, M. M.; Rossmanith, E.; Rüger, N.; Strand, E.; Souissi, S.; Stillman, R. A.; Vabø, R.; Visser, U.; DeAngelis, D. L. (2006) “A standard protocol for describing individual-based and agent-based models”, ECOLOGICAL MODELLING 198, 115-126.
Grimm, V.; Berger, U.; DeAngelis, D.L.; Polhill, J.G.; Giske, Jarl & Railsback, S.F. (2010) “The ODD protocol: a review and first update”, Ecological Modelling 221(23), 2760-2768.
Hanneman, R. A. (1988) Computer-Assisted Theory Building: Modelling Dynamic Social Systems. Newbury Park, CA: Sage.
Harrè, R. (1972) The Philosophies of Science. An Introductory Survey, Oxford: Oxford University Press.
Hedström, P. (2010) “La explicación del cambio social: Un enfoque analítico”, en José A. Noguera (comp.) Teoría Social Analítica, Madrid: CIS, Col. Academia 31, 211-235.
Hedström, P. & Bearman, P. (eds.) (2009) The Oxford Handbook of Analytical Sociology. Oxford: Oxford Univ. Press.
Hedström, P. & Bearman, P. (2009) “What is analytical sociology all about? An introductory essay”, en Hedström & Bearman (eds.) The Oxford Handbook of Analytical Sociology. Oxford: Oxford Univ. Press, 3-24.
Hedström, P. & Ylikosky, P. (2010) “Causal Mechanisms in the Social Sciences”, ANNUAL REVIEW OF SOCIOLOGY 36:49-67.
Hegselmann, R. (1996) “Understanding social dynamics: the cellular automata approach”, en Troitzsch, Mueller, Gilbert & Doran (eds.) Social Science Microsimulation. Berlin: Springer, pp. 282-306.
Helbing, D. (1994) Quantitative Sociodynamics: Stochastic Methods and Models of Social Interaction Processes. Dordrecht: Kluwer.
Holland, J. H & Miller, J.H (1991) “Artificial adaptive agents in economic theory”, American Economic Review 81(2): 365-370.
Huhns, M.N. & Singh, M.P. (Eds.) (1997) Readings in Agents. San Francisco, CA: Morgan Kaufmann.
Izquierdo, J.L; Galán, J.M.; Santos, J.I. & del Olmo, R. (2008) “Modelado de sistemas complejos mediante simulación basada en agentes y mediante dinámica de sistemas”, EMPIRIA. Revista de Metodología de Ciencias Sociales 16: 85-112.
Janssen, Marco A. (2009) “Understanding Artificial Anasazi”. JASSS, Journal of Artificial Societies and Social Simulation 12(4)13. <https://jasss.soc.surrey.ac.uk/12/4/13.html>
Kahn, Ken & Noble, Howard (2010) “The Modelling4All Project : A web-based modelling tool embedded in Web 2.0 ”, comunicación en CONSTRUCTIONISM 2010 (16-20 Agosto, Paris). The American University of Paris & EuroLogo. <https://modelling4all.wikidot.com/local—files/publications/M4A%20Constructionism%202010v3.pdf>.
Klüver, J. (1998) “Modelling science as an adaptive and self-organising social system: concepts, theories and modelling tools”, en Ahrweiler & Gilbert (eds.) Computer simulations in science and technology studies. Berlin: Springer.
Kreutzer, W. (1986) System Simulation: Programming Styles and Languages. Sydney: Addison Wesley.
León, F.; Miguel, F.J. & Alcaide, V. (2010) “Collective Action and Social Networks: Multi-agent Simulation of a Network Protocol for the Production of Step-level Public Goods”, comunicación en XVII ISA World Congress of Sociology, Gothemburg (Suecia), Julio 2010.
Lozares, C. (2004) “La simulación social, ¿una nueva manera de producir ciencia sociológica?”. PAPERS, Revista de sociología 72:165-188.
Mackie, J.L. (1974) The cement of the universe; a study of causation. Oxford: Clarendon Press, 1974.
Macy , M. & Flache, A. (2009 ) “Social dynamics from the bottom up: agent-based models of social interaction”, en Hedström & Bearman (eds.) The Oxford Handbook of Analytical Sociology. Oxford: Oxford Univ. Press, 245-268.
Macy, Michael W.; Centola, Damon; Flache, Andreas; Van De Rijt, Arnout; Willer, Robb (2011) “Social mechanisms and generative explanations: computational models with double agent”, en P. Demeulenaere (ed.) Analytical Sociology and Social Mechanisms, Cambridge: Cambridge University Press.
Malerba, F.; Nelson R.; Orsenigo L. & Winter, S. (2001) “Competition and Industrial Policies in a 'History-Friendly' Model of the Evolution of the Computer Industry”, International Journal of Industrial Organization 19, 613-634.
Manzo, Gianluca (2011) “Relative deprivation in silico: agent-based models and causality in analytical sociology”, en P. Demeulenaere (ed.) Analytical Sociology and Social Mechanisms, Cambridge: Cambridge University Press.
Miguel, F.J. (2009) “Acceptability and Complexity: the Social Scientist Dilemma, and a ABSS Methodology case example”. INTELIGENCIA ARTIFICIAL, Revista Iberoamericana de IA 13(42): 21-35. <https://erevista.aepia.org/index.php/ia/article/view/595>
Miguel, F.J. (ed.) (2009) Social Simulation and Artificial Societies Analysis: Proceedings of the 2nd Workshop on Social Simulation and Artificial Societies Analysis (SSASA'08). Aachen : M. Jeusfeld c/o Redaktion Sun SITE, Informatik V, RWTH . CEUR Worshop Proceedings 442. <https://ftp.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-442/>
Moss, S.; Gaylard, H.; Wallis, S. & Edmonds, B. (1988) “SMDL: a multi-agent language for organizational modelling”. Computational and mathematical organization theory 4(1): 43-70.
Moss, Scott (2002) “Policy analysis from first principles”. Proceedings of the National Academy of Sciences, 99(Supl. 3), 7267-7274 <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC128596>.
Moss, Scott (2008) “Alternative Approaches To the Empirical Validation of Agent-Based Models”, JASSS, Journal of Artificial Societies and Social Simulation, 11(1): <https://jasss.soc.surrey.ac.uk/11/1/5.html >.
Neves, J.; Santos, M. & Machado, J. (eds.) (2007) EPIA 2007, LNAI 4874, Berlin,Heidelberg: Springer-Verlag.
Newell, A. & Simon, H.A. (1972) Human problem solving. Englewood Cliffs, N.J.: Prentice-Hall.
Ostrom, Th. (1988) “Computer simulation: the third symbol system”. Journal of Experimental Social Psychology 24:381-392.
Railsback, S.; Lytinen, S. & Jackson, S. (2006) “Agent-based simulation platforms: review and development recommendations”. SIMULATION, 82(9): 609-623.
Ramanath, A.M. & Gilbert, N. (2004) “The Design of Participatory Agent-Based Social Simulations”. JASSS, Journal of Artificial Societies and Social Simulation 7(4)1. <https://jasss.soc.surrey.ac.uk/7/4/1.html>
Rouchier, J. (2003) “Re-implementation of a multi-agent model aimed at sustaining experimental economic research: The case of simulations with emerging speculation”. JASSS, Journal of Artificial Societies and Social Simulation 6(4)7. <https://jasss.soc.surrey.ac.uk/6/4/7.html>.
Schut, M.C. (2007). Scientific handbook of simulation of collective intelligence. Publicado bajo licencia Creative Commons licence. Disponible en <https://www.mpcollab.org/MPbeta1/node/143>.
Shannon, R.F. (1975): Simulation: A Survey with Research Suggestions, AIIE Transactions. Vol. 7, No. 3, Sept. 1975.
Terna, P. (1998) “Simulation Tools for Social Scientists: Building Agent Based Models with SWARM”. JASSS, Journal of Artificial Societies and Social Simulation 1(2) <https://www.soc.surrey.ac.uk/JASSS/1/2/4.html>.
Troitzsch, K.G. (1997) “Social Simulation: origins, prospects, purposes”, en Conte, Hegselmann & Terna (eds.) Simulating Social Phenomena. Berlin: Springer-Verlag, Lecture Notes in Economics and Mathematical Systems, Vol. 456: 41-54.
Troitzsch, K.G.; Mueller, U.; Gilbert, N. & Doran, J.E. (ed.) (1996) Social Science Microsimulation. Berlin: Springer.
Von Neumann, J. (1966) The Theory of Self-reproducing Automata. Urbana, IL.: Univ. of Illinois Press, A. Burks Ed.
Wooldridge, M. & Jennings, N. R. (1995) “Intelligent agents: theory and practice”. Knowledge Engineering Review 10(2):115-152.
Woolgar, S. (ed.) (1988) Knowledge and reflexivity: new frontiers in the sociology of knowledge. London: Sage.
Zizzo, D.J. (2001) “Review of: Neural Networks: An Introductory Guide for Social Scientists”. JASSS, Journal of Artificial Societies and Social Simulation, 4(3). <https://jasss.soc.surrey.ac.uk/4/3/reviews/garson.html>
[1] Críticas habituales contra la “competencia perfecta”, la “información perfecta”, la “racionalidad perfecta” y otras idealizaciones utilizadas en el ámbito de la Economía.
[2] La inferencia de “resultados” del modelo depende del tipo de representación del mismo: análisis para modelos matemáticos, estimación para modelos estadísticos, o ejecución para modelos informáticos; en los dos últimos casos es necesario disponer de datos fiables del sistema social simulado, para lo cual se emplean técnicas habituales de recopilación de datos sociológicos (Gilbert & Terna, 2000; Gilbert, 2008).
[3] Tal vez las principales excepciones a esta distribución se puedan encontrar en las disciplinas demográficas, económicas, la investigación comercial y organizacional, que priorizan el uso predictivo.
[4] Curiosamente, uno de los principales objetivos y estímulos iniciales del desarrollo de la simulación por ordenador y la inteligencia artificial, el juego del ajedrez (Newell & Simon, 1972), en realidad no es a su vez más que una simulación física correspondiente a la modelización de un fenómeno social, la batalla entre dos ejércitos, con orígenes documentados que se remontan hasta antes de siglo VI.
[5] El ejemplo paradigmático y clásico de esta técnica de simulación es el llamado “juego de la vida” de Conway en el que cuatro reglas de comportamiento muy simples gobiernan un sistema de autómatas celulares que simula un complejo comportamiento agregado similar a la vida de una sociedad de organismos complejos que interaccionan entre sí (Gardner, 1970).
[6] Otro criterio fundamental para optar entre modelizar según las modalidad SD o MAS es atender al nivel de abstracción de los objetivos de la investigación (Izquierdo et al., 2008: 105).
[7] Cada “Rule Master” puede implementarse mediante un sistema de producción, o un sistema de clasificación, o una red neuronal, o un algoritmo genético, o una red bayesiana, o cualquier otro dispositivo generador de información.
[8] Frecuentemente ambos tipos de emergencia se presentan en el mismo modelo de simulación (Terna, 1998).
[9] “reflexive and situated knowledge” (Giddens, 1984), “reflexivity” Woolgar (1988), “second-order emergence” según Gilbert (1995).
[10] En el diseño de SSBA los métodos relacionados con las redes artificiales neuronales se utilizan, no tanto como herramienta de análisis sino como instrumento de modelización de los procesos cognitivos y decisionales de los agentes (Zizzo, 2001).
[11] Ambas analogías pueden ser capturadas mediante sistemas de producción, en especial la idea de evolución morfológica o normativa de poblaciones mediante la simulación a largo plazo temporal de mecanismos basados en el algoritmo genético. Cada individuo posee un grado de adaptación (fitness) al entorno, definido por una métrica concreta. Con el paso del tiempo los individuos mejor “adaptados” se emparejan preferentemente y su reproducción genera descendientes que comparten características propias de ambos progenitores, lo que resulta en un incremento promedio de la adaptación de la población al entorno (para un ejemplo de utilización en SSMA, véase Chattoe & Gilbert, 1997).
[12] El paradigma BDI (Bratman, 1987) consiste en una teoría psicológica y filosófica, relacionada con la teoría de la elección racional, que ha sido incorporada al diseño de agentes en la informática y popularizada en numerosas aplicaciones. Fundamentalmente establece que los actores orientan sus comportamientos racionalmente, en base a un subconjunto de creencias (representaciones de la realidad), deseos (motivaciones) e intenciones (objetivos).
[13] Pueden encontrarse un par de herramientas simples de diseño UML en <https://www.umlet.com/> y <https://alexdp.free.fr/violetumleditor/page.php>.
[14] Algunos ejercicios consistentes en la programación del mismo modelo usando implementaciones, entornos y lenguajes diversos han reportado una gran diversidad en cuanto a la eficiencia técnica, aunque lo relevante es la identidad en cuanto a los resultados finales de la ejecución de simulación (Railsback et al., 2006).
[15] Al contrario que otras, como por ejemplo la simulación “dinámica de sistemas” mediante sistemas de ecuaciones diferenciales.
[16] Algunos entornos de programación de SSBA son especialmente adecuados para estas tareas de depuración dado que disponen de un “objeto”, adicional al modelo, que puede recopilar y mostrar información detallada sobre los estados intermedios del sistema completo y de cada agente (el nivel “Observador” de Netlogo o Swarm).
[17] Tal como lo expresan, de manera informal y rigurosa, Izquierdo & Galán: “...podríamos decir que verificar consiste en valorar si el modelo que tenemos es correcto, mientras que validar consiste en estudiar si tenemos el modelo correcto.” (2008: 89).
[18] La fiabilidad y la validez de un modelo de simulación social son independientes, hasta tal punto que nada impide la existencia lógica de modelos de simulación válidos (predicciones o postdicciones ajustadas a la realidad empírica) pero no fiables (implementan incorrectamente el sistema de hipótesis en el que se basan). Por ello la verificación de la fiabilidad de un modelo debe realizarse de forma independiente, y previa, al análisis de su validez explicativa.
[19] Un efecto está sobredeterminado cuando tiene dos causas independientes, cada una suficiente por sí sola para producir el efecto (Mackie, 1974).
[20] Por ejemplo, en un estudio sobre el proceso de decisión individual sobre la aportación de recursos para obtener bienes públicos de uso general, las simulaciones realizadas a partir de un modelo abstracto permiten identificar como factores explicativos más relevantes la información disponible en el momento de decidir y la concurrencia de la decisión (simultánea, sucesiva, con orden conocido o desconocido,...), por encima de otros factores destacados hasta el momento por la literatura al respecto, como el tamaño del grupo o la topología de la red social (León et al., 2010).
[21] Por ejemplo, Malerba et al. (2001) simulan con su modelo la evolución histórica de la industria informática, consiguiendo replicar la ocurrencia de los principales sucesos mediante ajustes de parámetros iniciales que se corresponden con presunciones teóricas fundamentales al respecto. Cambios en los escenarios iniciales proporcionan igualmente historias alternativas coherentes, por lo que los autores describen su modelo como “history-friendly”.
[22] Dean et al. (2000) replicaron, a partir de la detallada información arqueológica disponible al respecto, el proceso de abandono del área de Long House Valley por parte del pueblo Anasazi entre 800 y 1350 AD, mediante la simulación de un modelo informático con 1250 individuos representados por 250 hogares-agentes (Janssen, 2009). Los resultados intermedios de esta simulación se contrastaron con los diversos registros históricos.
[23] Véase, como ejemplo, el repositorio de código desarrollado por la comunidad de programadores de modelos NetLogo, <https://ccl.northwestern.edu/netlogo/models/community>.
[24] Si se utiliza el protocolo ODD se debe hacer referencia según la formulación: “La descripción del modelo sigue el protocolo ODD (Overview, Design concepts, Details) según Grimm et al. (2006; 2010).”.
[25] Excepto para planificaciones muy simples, es conveniente usar pseudo-código para describir la planificación, sin comprometerse con ningún lenguaje concreto de implementación del modelo.
[26] MAS-CommonKADS (para metodología CommonKADS), MaSE (orientada a objetos), TROPOS (desarrollo simplificado pero no es totalmente de dominio público) e INGENIAS (extensión de MESSAGE/UML y con generación de código automática).
[27] En España, es el caso de los primeros trabajos de los equipos del IIIA-CSIC, de GRASIA y de INSISOC. Participantes pioneros en tales experiencias han reconocido que no es esta la situación ideal, en la que el investigador social, “conocedor del modelo sociológico, pudiera servirse de esta herramienta de forma autónoma” (Arroyo & Hassan, 2007: 144).
[28] Esto implica formación de postgrado especializada, en las escasas instituciones que disponen de tal oferta (ZUMA Workshop en Koblenz, ESSA Summer School, CRESS de Surrey, CfPM de Manchester).
[29] “One goal of Swarm is to bring simulation writing up to a higher level of expression, writing applications with reference to a standard set of simulation tools” (Documentación de SWARM, https://swarm.org/).
[30] En computación, se denomina lenguaje high-level al que resulta comprensible y cercano al lenguaje natural humano debido a su abstracción respecto a los detalles concretos de la máquina sobre la que se ejecuta. Contrariamente, un lenguaje-máquina está formado por la descripción en bits (1/0) de posiciones de memoria ejecutables para un procesador en concreto.
[31] Entre los planes de desarrollo actual del sistema Modelling4All se incluye la incorporación de otros lenguajes de programación para los modelos generados, entre otros Repast. Igualmente, el desarrollo actual incluye la visualización de los resultados de ejecución Netlogo dentro de plataformas de información geográfica (Google Maps) y de realidad virtual (Second Life) utilizando los elementos e interfaces propios de tales plataformas (Kahn & Noble, 2010).
