
Mari-Carmen Marcos (Universitat Pompeu Fabra)
Citación recomendada: Mari Carmen Marcos. Elementos visuales en sistemas de búsqueda y recuperación de información [en línea]
1. Introducción
2. La visualización de la colección (overview)
2.1. Mapas autoorganizativos (Self Organizing Maps, SOM)
2.2. VxInsight
2.3. Cat-a-Cone
3. Visualización del conjunto de resultados (preview)
3.1. BEAD (Chalmers; Chitson, 1992)
3.2. SPIRE (Spatial Paradigm for Information Retrieval)
3.3. JAIR
3.4. NIRVE
3.5. PRISE
3.6. Perspective Wall
3.7. VIBE
4. Visualización de atributos de los documentos
4.1. TileBars
5. Conclusiones
6. Bibliografía
"The next generation of animated GUIs and visual data mining tools can provide users with remarkable capabilities if designers follow the Visual Information-Seeking Mantra:
"Overview first, zoom and filter, then details-on-demand.
Overview first, zoom and filter, then details-on-demand.
Overview first, zoom and filter, then details-on-demand.
Overview first, zoom and filter, then details-on-demand..."
(Ben Shneiderman)
Con este mantra Ben Shneiderman profetiza en muchos de sus artículos y conferencias lo que será la próxima generación de interfaces de recuperación de información: primero una visión general, después un acercamiento y un filtro, y por último detalle de la parte que interesa. Shneiderman está sintetizando así cuatro etapas del proceso de búsqueda de información, y a todas ellas añade un componente visual:
El usuario llega al sistema y ve de forma global qué información puede obtener en él, qué materias abarca, cuál es la forma de funcionamiento.
Una vez visto de forma general, el usuario efectúa un zoom, es decir, se centra en una parte que le resulta de mayor interés.
Para afinar mejor su búsqueda aplica un filtro, de manera que los resultados obtenidos sean más precisos a su necesidad de información
Para terminar el proceso, el usuario solicita tener más datos de algunos de los resultados, con el fin de determinar si será de su interés.
En el mantra se refiere a "animated GUIs and visual data mining tools", y hacemos hincapié en "visual" para continuar este artículo. El área de la visualización de información trata de ofrecer representaciones visuales que comuniquen la información de una forma rápida y efectiva. Se han ideado diversas técnicas que se dirigen a este objetivo y que hacen del proceso de recuperación de información una tarea más comprensible y en ocasiones más interactiva. Enumeramos las más empleadas:
utilización de iconos para representar conceptos
empleo de colores y texturas para destacar o diferenciar elementos
gráficos con presentaciones jerárquicas que facilitan el ojeo
mapas que presentan información agrupada en función de su similitud empleando técnicas de agrupación
efectos de zoom para mostrar información con detalle
animación y perspectiva en tres dimensiones
La visualización aplicada a la información ayuda a las personas a formar una imagen mental del espacio informativo. Si la visualización tiene lugar en una interfaz cuyo objetivo es la recuperación de información, la expresión acuñada para este tipos de sistemas es "interfaces visuales de recuperación de información" (VIRIs, Visual Information Retrieval Interfaces).
Los cuatro procesos nombrados anteriormente son susceptibles de ser presentados mediante componentes visuales. De hecho, en los siguientes apartados vamos a ver algunos sistemas de presentación de información-en su mayoría proyectos que no han llegado a tener una implementación a nivel comercial- que servirán de ejemplo para mostrar estos elementos de visualización. Se ha optado por clasificarlos en tres grupos: visión global de la colección, visualización de los resultados, y visualización de los atributos de cada documento.
Quedaría por abordar la última fase del proceso de búsqueda y recuperación de información, que enlaza el momento de presentación de los resultados obtenidos por el sistema con la consulta. Se trata de la reformulación de la consulta, para lo que por el momento no se ha empleado la visualización, por lo que este punto no será tratado.
En el caso de la visualización de la colección completa (overview), el objetivo es evitar que el usuario se enfrente a una "caja de consulta" en la que debe expresar de la mejor manera posible su necesidad de información por medio de unos descriptores.
La dificultad que entraña esta acción para el usuario nos lleva a pensar en soluciones de este tipo, en donde el sistema presenta una visión general del contenido de la base de datos y el usuario escoge por donde continuar profundizando. Por lo tanto, la carga cognitiva que recae sobre él es mucho menor si selecciona ítems (entradas, temas...) que si formula la búsqueda.
La técnica de presentación de bases de datos completas por antonomasia es el mapa (entendido como representación cartográfica, no como una jerarquía textual): en una sola pantalla el usuario obtiene una imagen global de la colección y a partir de ella interactúa para descender a niveles más específicos siguiendo una ruta jerárquica y/o asociativa.
2.1. Mapas autoorganizativos (Self Organizing Maps, SOM)
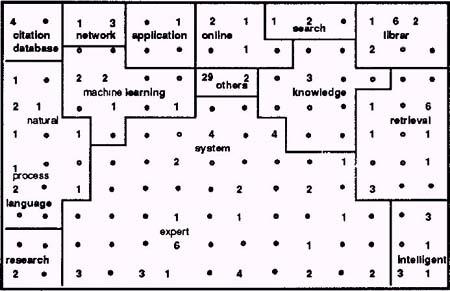
Lin (1992, 1997) propone la visualización a posteriori. Aplicando el algoritmo de aprendizaje no supervisado de Teuvo Kohonen -investigador de redes neuronales-, Lin crea unos mapas autoorganizativos (Self Organizing Maps, SOM) basados en la indización. Las áreas son proporcionales en tamaño a la frecuencia de aparición de los términos y pueden ser mostradas en diferentes colores. Los términos que co-ocurren con mayor frecuencia se colocan en una misma área o en una cercana. Para ver a qué se refiere cada punto, se pulsa encima y se obtiene la información del documento al que representa.
Figura 1. Mapa tipo SOM (Lin, 1991), realizado a partir de los resultados de una búsqueda en la base de datos LISA, http://faculty.cis.drexel.edu/~xlin/fulltext/ACM91.pdf
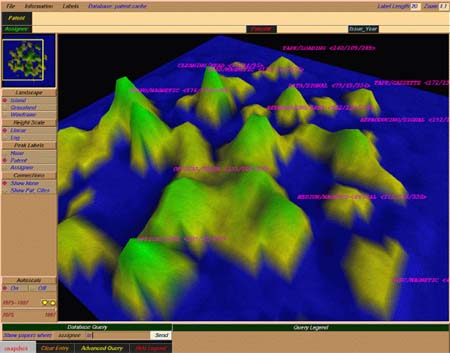
Los Sandia National Laboratories usan en su sistema VxInsight la metáfora de las islas de Polinesia para presentar la bibliografía científica basándose en las citas. En este sistema las disciplinas comprenden rangos de montañas, y se pretende que sirva para detectar nuevas áreas de estudio y aquellas que se van uniendo entre sí (volando alto en un entorno de realidad virtual) y para ver los subcomponentes de las disciplinas (volando bajo), incluso los títulos de los artículos situados en la zona (volando más bajo aún). El uso de estas metáforas no es nuevo. La figura 2 muestra un ejemplo.
Figura 2. VxInsight. De los Sandia National Laboratories, crea visualizaciones con usando la metáfora del terreno, http://www.cs.sandia.gov/projects/VxInsight/snapshot.html
http://www.sims.berkeley.edu/~Hearst/cac-overview.html
También Cat-a-Cone apuesta por la presentación de categorías jerárquicas, pero lo hace de forma simultánea a los documentos resultantes de la búsqueda y usando una animación en 3D donde las jerarquías se presentan en forma de conos que giran para permitir ver los que quedan en la parte de detrás. Como se observa en la figura 3, su interfaz muestra una jerarquía temática en la que el usuario puede hacer un ojeo e ir escogiendo materias, y al mismo tiempo superpone en la pantalla los registros de los documentos recuperados y lo hace en forma de libro abierto.
El objetivo de este sistema es facilitar la recuperación de los documentos utilizando los encabezamientos de materia y ofrecer tanto la estructura temática como los resultados en una misma interfaz (Hearst, Karadi, 1997).
Figura 3. Cat-a-Cone. De Xerox Parc, presenta la jerarquía temática con conos y al mismo tiempo el documento que el usuario marca, http://www.sims.berkeley.edu/~hearst/papers/cac-sigir97/survival.jpg
En el caso de la visualización para presentar los resultados de una búsqueda, se puede optar por soluciones similares a las presentadas cuando se ofrece una visión global de la colección, pero con dos particularidades: por un lado, el número de documentos va a ser menor (por tanto el cálculo algorítmico para efectuar visualizaciones se simplifica); por otro lado, las relaciones entre documentos van a variar en función de los que se hayan seleccionado, lo que quiere decir que la presentación va a variar en cada conjunto de resultados (es una presentación dinámica, no estática como podría ocurrir al visualizar toda la colección completa) y eso complica los cálculos algorítmicos.
3.1. BEAD (Chalmers; Chitson, 1992)
Es un proyecto de visualización de datos multivariables complejos en recuperación de información En este caso, las comparaciones entre documentos se hacen recurriendo a un gran número de variables. Estas condiciones no son idóneas para los métodos de visualización y los análisis en gráficos conocidos, por eso el prototipo presentado de ojeo de información basada en gráficos utiliza un espacio tridimensional en el que representa los artículos como partículas (se recurre a la metáfora del magnetismo entre partículas): las relaciones entre artículos vienen representadas por su posición relativa en el espacio; la fuerza entre partículas tiende a ubicar los artículos más similares más cercanos que los menos similares. El resultado es una escena en tres dimensiones que puede usarse para visualizar modelos en un espacio multidimensional (véase la figura 4).
Figura 4. BEAD. En este ejemplo de BEAD se presenta el cluster principal de documentos recuperados con el descriptor "Information Retrieval", sobre los que podría efectuarse un zoom, http://www.dcs.gla.ac.uk/~matthew/papers/sigir92.pdf

Por tanto, BEAD utiliza las técnicas de simulación de la física para modelar documentos como partículas en espacios tridimensionales, concretamente la técnica que se utiliza para simular la cocción de los metales para mejorar el algoritmo de escalado multidimensional (MDS) para la agrupación de documentos. Una vez que los documentos están agrupados en clusters, el usuario introduce los términos de búsqueda y el sistema responde con códigos de colores en cada documento según la relevancia con respecto a la consulta. El usuario puede hacer un zoom en los artículos que parecen de su interés. Lamentablemente, el resultado del experimento realizado en el año 1992 es demasiado lento: 18 minutos para 100 partículas.
3.2. SPIRE (Spatial Paradigm for Information Retrieval)
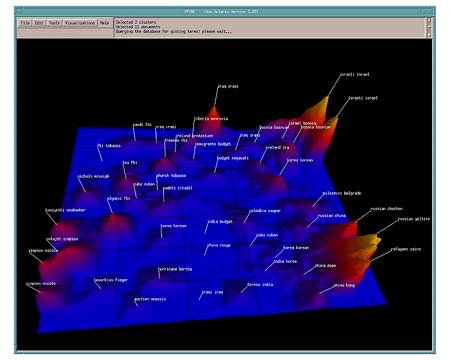
En el proyecto SPIRE (Spatial Paradigm for Information Retrieval) del Pacific Nortwest National Laboratorios (http://www.pnl.gov/infoviz), se han desarrollado diversas metáforas de visualización. Comentamos dos de ellas. La primera, Galaxies (véase la figura 5) , hace que los documentos aparezcan como estrellas y están agrupados entre sí como constelaciones, y éstas entre sí, y todo teniendo como base la co-ocurrencia estadística. De esta forma, un vistazo sirve para ver fácilmente los temas y dirigirse al que interesa, y dentro de esa zona ahondar más para ver qué documentos incluye cada cluster.
La otra metáfora es la del paisaje y se usa en ThemeView (antes llamado Themescape). En este caso se toma el cuerpo de los documentos y se representa con valles y montañas basándose en la frecuencia estadística de las palabras clave: cuanto más relevante es un documento más alta es la montaña que lo representa; los valles muestran la ausencia de palabras clave.
La novedad que incorporan los autores es que el cuerpo de documentos ronda los 20.000 y pueden ser presentados en mapas en línea (véase la figura 6).
Figura 5. Galaxies. Presenta los documentos agrupados por similitud, http://www.pnl.gov/infoviz/galaxy800.gif
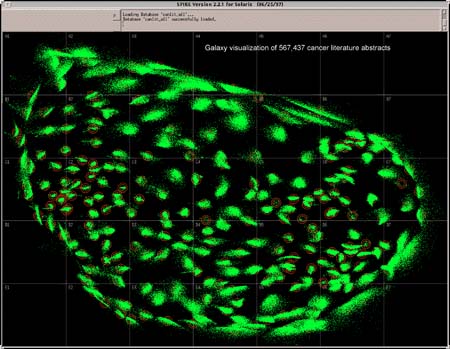
Figura 6. ThemeView. De los Pacific Nortwest National Laboratories, representa con valles y montañas basándose en la frecuencia estadística de las palabras clave http://www.pnl.gov/infoviz/themeview800.gif
JAIR (Foltz, 1997) se creó para ofrecer acceso a la revista Journal of Artificial Intelligence Research (JAIR) a los especialistas interesados en el tema. Por lo tanto, partimos de la base de que se trata de un sistema no referencial, sino a texto completo, y dirigido a personas que conocen el vocabulario específico de la materia sobre la que se da información. En este caso se optó por una representación bidimensional de los documentos, si bien se contempla una tercera dimensión para ofrecer información adicional. Por medio de la representación en 2D el usuario puede centrar su interés en una parte de los resultados (focus) y tener la impresión de que está explorando un objeto en lugar de estar viendo una imagen sin más.
Figura 7. JAIR. Clasifica los artículos en categorías tomadas del sistema de clasificación de la ACM, http://www.infoarch.ai.mit.edu/JAIR/JAIR-help.html
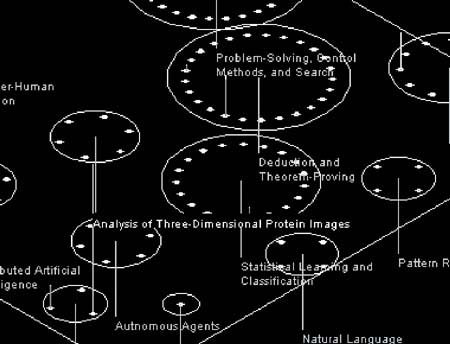
En JAIR, para diseñar la presentación de los iconos no se han tenido en cuenta las consultas almacenadas ni se han basado en la similitud de términos creando vectores, sino que se ha optado por clasificar los artículos en categorías tomadas del sistema de clasificación de la ACM de 1991. Con esta referencia se ha creado una estructura de jerarquía en dos niveles: un primer posicionamiento entre categorías y un segundo nivel con los documentos dentro de las categorías.
Un mismo artículo puede ser incluido en dos categorías. Esta estructura es similar a la de "cone tree" (Robertson, Mackinlay y Card, 1991) pero sin ser multinivel. Los artículos se colocan en la presentación de forma equidistante en función del centro de cada categoría y el radio de éstas es proporcional a la raíz cuadrada del tamaño de la categoría, de manera que el área es proporcional al tamaño (véase la figura 7). Se utiliza el algoritmo de escalamiento multidimensional de Kruskal (1964a, 1964b) para colocar los centros de las categorías y encontrar una configuración en la que el orden de disimilitudes se preserve en las distancias entre categorías, pero se tuvo que ser modificado para que no hubiera solapamiento entre categorías. El resultado es que cuantos más artículos comparten las categorías más cerca se encuentran entre sí.
En JAIR, además, se ha recurrido al uso de colores para enfatizar los elementos de visualización. Como posibilidades para el usuario indicamos la búsqueda en texto completo, el listado o historial de búsquedas, la opción de modificar búsquedas que se encuentren en el historial para crear nuevas consultas, y poder visualizar la referencia, el resumen o el texto completo según se desee en cada documento. Además, al acceder a un documento automáticamente se muestra una lista de los artículos relacionados.
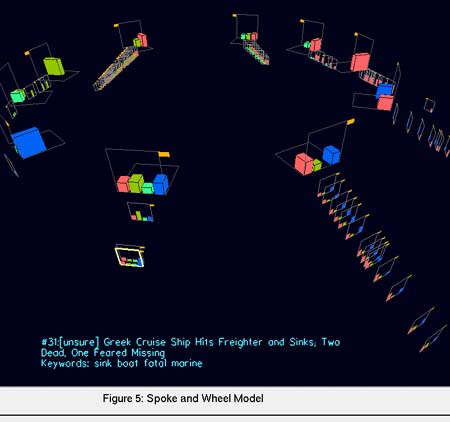
Un ejemplo muy significativo de representación de documentos obtenidos en unan consulta en un sistema de recuperación de información mediante agrupación (clustering) es el caso de NIRVE (NIST Information Retrieval Visualization Engine) (Cugini, Laskowski y Sebrechts, 2000) (http://zing.ncsl.nist.gov/~Cugini/uicd/NIRVE-home.html). En este sistema cada documento recuperado incluye el título del documento, un identificador único, la relevancia con respecto a la consulta, el tamaño del documento y el número de ocurrencias de cada descriptor que lleva asignado.
La pantalla se organiza en dos ventanas: una de documentos con los títulos, los clusters, los descriptores y los conceptos; otra de control de las operaciones que no se pueden mostrar de forma natural en el espacio de documentos (es decir, en una el gráfico y en otra las opciones). El usuario puede crear un conjunto de descriptores de la consulta en un concepto y ese concepto puede tener asignado un nombre y un color. La asociación de descriptores y conceptos se muestra con una leyenda interactiva en la parte inferior de la ventana de documentos (bajo el gráfico).
Para cada documento se crea un perfil de concepto según la frecuencia con la que aparecen los descriptores de ese concepto; de esta manera un cluster sería un conjunto de documentos que comparten un subconjunto de conceptos. Cada cluster se representa como una cajita con barras de colores que indican el perfil de concepto medio de sus documentos; cuantos más documentos contenga el cluster, más grande se representa la caja (véase la figura 8).
Figura 8. NIRVE. Representación en 3D de los clusters en forma de cajas de colores que indican el concepto medio de los documentos que lo conforman, y cuyo tamaño es indicador del número de documentos que contiene, http://www.itl.nist.gov/iaui/vvrg/Cugini/uicd/NIRVE-paper.html
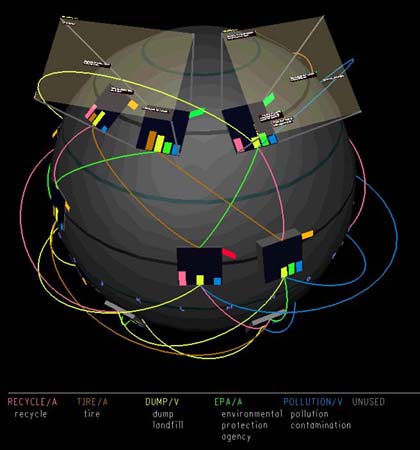
La representación de NIRVE se ha probado a hacer con distintas metáforas, por ejemplo la del globo, en la que los iconos de los clusters se colocan en la superficie de un globo (una esfera, véase la figura 9) donde la latitud viene determinada por el número de conceptos del cluster (cuantos más conceptos, más cerca del polo norte). Los iconos se colocan de manera que los clusters con más conceptos en común estén más cerca entre sí. Si dos clusters difieren entre sí por un solo término, entonces se dibuja un arco que los une y que tendrá el color asignado al concepto diferente.
Figura 9. NIRVE. Metáfora del globo, http://www.itl.nist.gov/iaui/vvrg/Cugini/uicd/NIRVE-paper.html
Cuando el usuario abre un cluster se proyecta un rectángulo en 2D que contiene los títulos de los documentos que integra; esos títulos están ordenados de forma que los documentos más similares se encuentran cercanos horizontalmente y los más relevantes se encuentran más arriba en la vertical. Si el usuario selecciona un título puede abrir el texto completo en el navegador web y ver cómo los descriptores aparecen destacados en el color que corresponde al concepto al que hacen referencia. Además, puede marcar documentos e incluso clusters enteros indicando si son de más o menos interés.
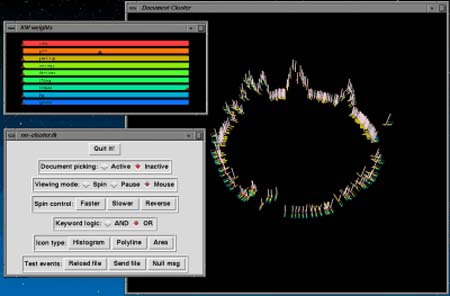
PRISE (Cugini, Piatko, Laskowski, 1996) aplica técnicas de clustering y vectorización, y consigue con ellas presentaciones visuales diferentes del listado habitual. La idea es mostrar la lista de documentos en diferentes formas, como una línea en forma de espiral siguiendo el orden de relevancia; o con un gráfico de tres ejes, cada uno correspondiente a un descriptor y mostrando así el espacio donde confluyen; o finalmente mediante una representación de las "vecindades" entre términos. Las figuras 10, 11 y 12 muestran un ejemplo de cada tipo.
Figura 10. PRISE. Presenta los documentos ordenados por relevancia siguiendo la línea de una espiral, http://zing.ncsl.nist.gov/~Cugini/uicd/viz.html
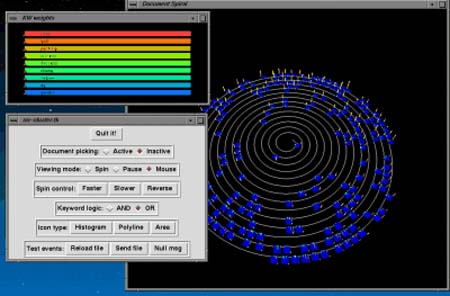
Figura 11. PRISE. Muestra cada descriptor en un eje y creo un espacio tridimensional en el que se representan los documentos, http://zing.ncsl.nist.gov/~Cugini/uicd/viz.html
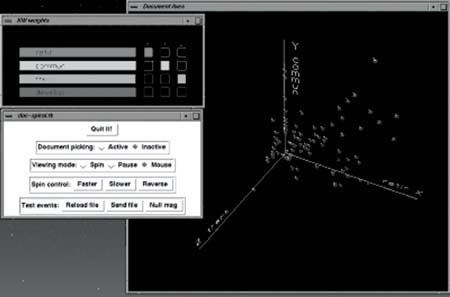
Figura 12. PRISE. Agrupa los documentos en esta representación según el grado de vecindad, http://zing.ncsl.nist.gov/~Cugini/uicd/viz.html
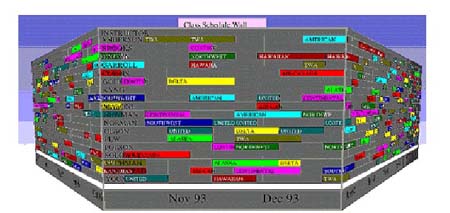
Perspective Wall (Mackinlay, Robertson, Card, 1991) (http://people.cs.vt.edu/~North/infoviz/perspectivewall.pdf) es uno de los más conocidos dentro de la visualización. Lo desarrolla Inxight. Este sistema simula a una pared tripartita que permite al usuario traer información al frente de la pantalla, mientras que al fondo se quedarían las otras dos partes. Los datos se muestran en dos dimensiones y el usuario puede ordenar los documentos en el eje de abscisas (x) por otro criterio distinto (véase la figura 13).
Figura 13. Perspective Wall. El usuario trae la información que le interesa ver a la pared de enfrente y deja otra contextual en las paredes laterales, http://people.cs.vt.edu/~North/infoviz/7
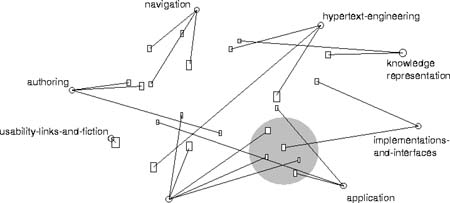
En VIBE (Olsen et al.; 1993; Korfhage, 1991, 1997) (http://www2.sis.pitt.edu/~WebVIBE/WebVIBE/page02.html) la presentación se hace a través de un mapa. Este sistema proyecta el estado de la búsqueda del usuario más que los atributos de toda la colección, y lo hace en dos dimensiones. El usuario comienza definiendo al menos dos puntos de interés (POI) con palabras clave que representen el espacio conceptual que busca, con lo que se crea un icono que se sitúa dentro de unas coordenadas. Por su parte, los documentos de la colección se comparan con el tema especificado por el usuario, se les da un vector de puntuación según correspondan a ese tema y se representan también con iconos. Para obtener información bibliográfica sobre cualquier icono simplemente se pulsa sobre él.
Por lo tanto, VIBE representa los resultados de una búsqueda en dos dimensiones donde la ubicación de los documentos en la pantalla viene determinada por su relación a los POIs. La similitud de los documentos entre sí y su cercanía conceptual a los POIs determinados se refleja en la colocación de los rectángulos (documentos) a los círculos (POIs). Las figuras 14 y 15 muestran un ejemplo de cómo presenta los resultados. En la recuperación se consideran relevantes todos aquellos documentos que contengan al menos uno de los descriptores señalados por el usuario al plantear la búsqueda. Los documentos con mayor coincidencia en sus descriptores con los del POI se colocarán más cerca de ese POI, pero siempre en relación al resto de los documentos.
El usuario puede también expandir los iconos de los documentos que le interesen, simplemente deberá dibujar un cuadrado alrededor del documento o documentos que le resulten de utilidad y se le mostrará en una ventana un listado de la selección efectuada. Al pulsar con el ratón sobre cualquiera de los documentos del listado se abrirá otra ventana con el documento completo.
Una característica que hace que este sistema sea interactivo es la de que el usuario puede añadir, cambiar o quitar los POIs de la pantalla. Para añadir uno deberá acudir a la lista de POIs o de términos indizados, elegir uno y moverlo con el ratón a la ubicación deseada en la pantalla de resultados. Al realizar cualquiera de estos cambios el sistema automáticamente lanza la consulta y reubica los documentos obtenidos para adecuar la presentación a las relaciones entre documentos y de éstos con los POIs.
Figura 14. VIBE. Esta pantalla muestra los resultados de una consulta hecha a partir de cinco términos. Algunos iconos de documentos han sido enlazados y los títulos de esos documentos se muestran en la caja de diálogo (Morse, Lewis, 1997), http://www.itl.nist.gov/iaui/vvrg/emorse/papers/smc97.html
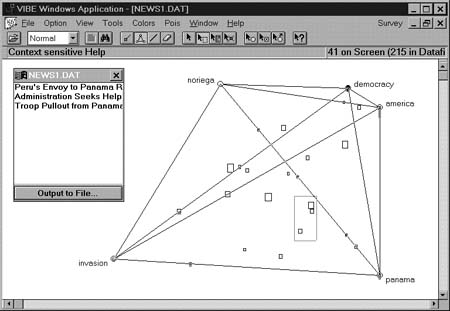
Figura 15. VIBE. Resultados de una búsqueda con VIBE (Imagen tomada de Hearts, 1999), http://www.sims.berkeley.edu/~Hearst/irbook/10/node7.html#fig:VIBE
WebVIBE
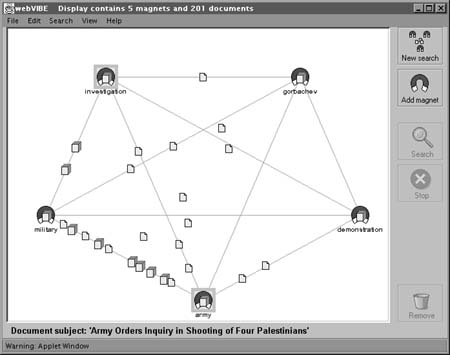
Web-VIBE, según explican Morse y Lewis (1997), representa los POIs con una metáfora de magnetismo y los convierte en imanes que atraen a los documentos, que se encuentran en un campo magnético. La posición de un documento viene determinada por la fuerza de atracción de los términos presentes en el documento, como muestran las figuras 16, 17 y 18.
Figura 16. WebVIBE. Resultado de una consulta con cinco términos. Dos iconos de puntos de interés (POI) están destacados para indicar que deben ser considerados como un criterio de relevancia. (Morse, Lewis, 1997), http://www.itl.nist.gov/iaui/vvrg/emorse/papers/smc97.html
Existe una versión online desarrollada en Java (http://www2.sis.pitt.edu/~WebVIBE/WebVIBE/) que está pensada para el usuario final. En estos momentos está en fase de evaluación, puede probarse en la web y enviar el cuestionario a sus desarrolladores para permitir su mejora.
Figura 17. WebVIBE. Pantalla de consulta con un Applet de Java en la web, http://www2.sis.pitt.edu/~WebVIBE/WebVIBE
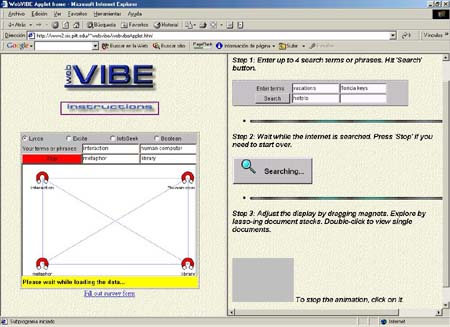
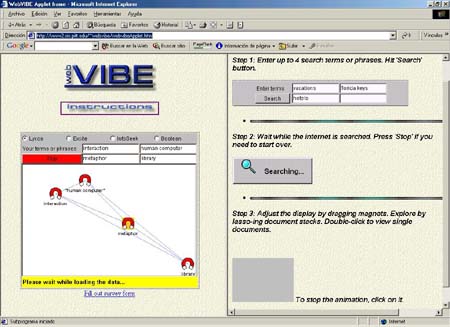
Figura 18. WebVIBE. Reajuste de los imanes (POI) por parte del usuario, http://www2.sis.pitt.edu/~WebVIBE/WebVIBE
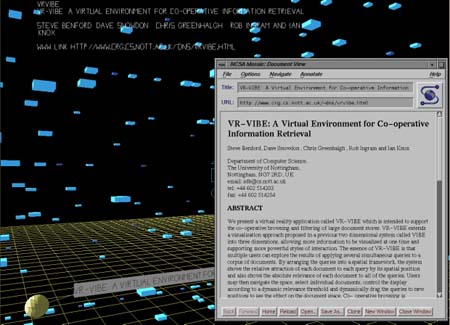
VR-VIBE
A partir de VIBE también se ha desarrollado VR-VIBE (Benford et al.; 1995) (http://www.crg.cs.nott.ac.uk/research/technologies/visualisation/vrvibe/), que representa la información en tres dimensiones y LyberWorld, pensado para documentos a texto completo (Hemmje et al.; 1994).
VR-VIBE ha sido elaborado por el Communications Research Group de la Universidad de Nottingham. Ha sido aplicado a visualizaciones en trabajo en grupo en un proyecto llamado "Populated Information Terrains". En él se definen cuatro formas de generar visualizaciones:
Mapas de coordenadas en los que se introducen los datos de las ordenadas y de las abscisas.
Hiper-estructuras en las que se muestran los enlaces entre objetos, por ejemplo, el esquema basado en el modelo entidad-relación, o la propia web. Las estructuras resultantes se pueden visualizar con técnicas de gráficos en tres dimensiones y aplicando técnicas de fish-eye, cone-trees (figura 19) y Perspective Wall.
Figura 19. ConeTrees. Técnica para visualizar hiperestructuras, http://www.crg.cs.nott.ac.uk/research/applications/pits/
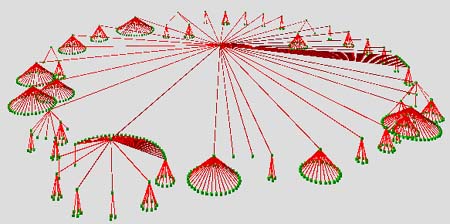
Diseño de la visualización mediante dos métodos: el primero consiste en crear metáforas del mundo real, como la biblioteca -en una base de datos de documentos-; ciudades, edificios y habitaciones -para organización de información en directorios- y mapas para información geográfica. En el segundo método, las personas construyen y organizan la información a su manera, por ejemplo sus ficheros en el "escritorio" de su ordenador.
Métodos estadísticos para analizar colecciones de datos que se agrupan por sus similitudes.
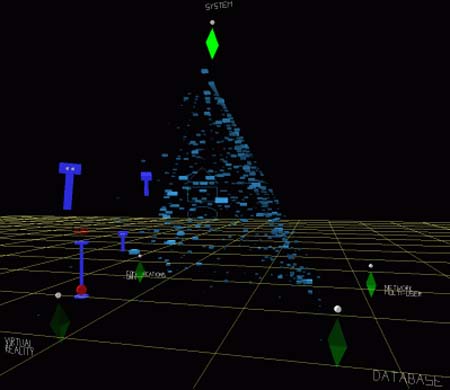
VR-VIBE va un paso más allá que su antecesor VIBE y crea visualizaciones de bibliografía en tres dimensiones. El usuario introduce los términos de su consulta y el resultado aparece representado en un espacio en 3D en el que los documentos recuperados se sitúan entre los descriptores de la consulta, más o menos cerca según la relevancia de cada uno respecto a cada descriptor. El color de los documentos también indica su grado de relevancia con respecto a los descriptores (cuanto más claros más relevantes). La figura 20 muestra dos ejemplos de este sistema.
Figura 20. VR-VIBE. Dos ejemplos de visualización de los documentos recuperados en un entorno de 3D, http://www.crg.cs.nott.ac.uk/research/technologies/visualisation/vrvibe
Por último, presentaremos el sistema TileBars, que presenta mediante visualización los atributos de los documentos recuperados.
Algunos sistemas dan una información añadida con aspectos que habitualmente no se contemplaban. Así, TileBars (Hearst, 1995) parte de la idea de que al recuperar documentos basándose en el título y el resumen se pierde información útil, por lo que defiende la búsqueda en texto completo. Además el autor considera que es importante que el usuario conozca la extensión del documento recuperado y la frecuencia de un descriptor en las distintas partes de la estructura del texto.
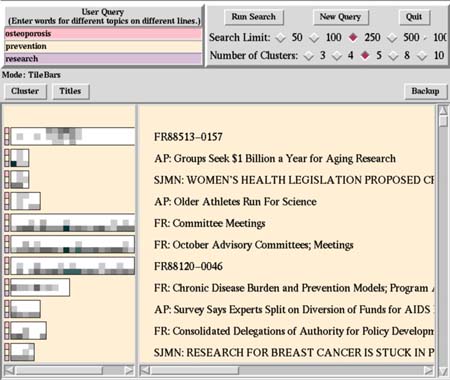
TileBars ofrece esta información de forma gráfica mostrando como resultado de la búsqueda el título de los documentos acompañado de un gráfico que consiste en un rectángulo en el que su largura muestra la extensión de cada documento y que al mismo tiempo se divide en tres filas, una para cada expresión de búsqueda planteada por el usuario. Dentro del rectángulo aparecen cuadros más o menos oscuros, según la frecuencia de aparición de cada expresión en cada parte del documento (véase la figura 21 para la explicación de esta barra y las figuras 22 y 23 como ejemplo de resultados en una base de datos médica y en una biblioteca digital respectivamente).
Previamente, un algoritmo al que han llamado TextTiling ha partido el documento en varias partes. De esta forma, si el primer término de búsqueda aparece con mucha frecuencia al inicio de un documento y con menos en la mitad de éste y de nuevo mucho en la parte final, el rectángulo mostrará en la primera fila (porque corresponde al primer término de búsqueda) cuadros oscuros al principio y al final de su largura y cuadros más tenues en la parte media.
Este método combina el listado ordenado de títulos relevantes con un gráfico que da información complementaria de cada documento recuperado. Está preparado para trabajar con documentos a texto completo. Este sistema también parte de la consulta del usuario y los resultados obtenidos.
Los documentos se representan como barras horizontales en las que se muestran las primeras palabras del título; estas barras contienen unos segmentos que representan las partes de los documentos; los segmentos están coloreados con mayor o menor oscuridad de la escala de grises, lo que indica la frecuencia con la que un término de la consulta coincide con las distintas partes de ese documento.
Figura 21. TileBars. La fila superior indica la frecuencia de la palabra "Information" en cada sección del documento, la inferior corresponde a Visualization. En el documento 2, de menor extensión que el 1, hay tres secciones en las que ambas palabras coinciden, http://www.infovis.net/Revista/2002/num_104.htm


Así, un segmento blanco indica que no hay ocurrencias comunes, uno gris que se dan entre 1 y 7 veces, y negro que se da 8 o más veces. La coocurrencia que pudiera darse entre los documentos (es decir, que coincidan en ellos los términos) se muestran en los segmentos con líneas verticales.
Figura 22. TileBars. Resultados en una base de datos médica con una consulta de tres términos. A la izquierda se presentan las barras y a la derecha los resultados, http://www.sims.berkeley.edu/~Hearst/tb-example.html
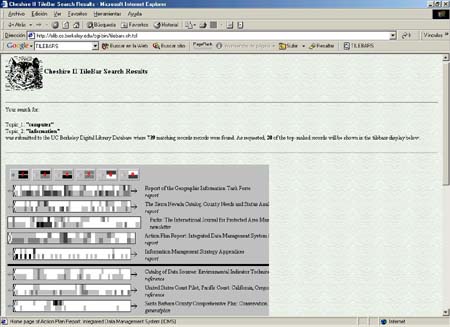
Recientemente, el Berkeley Digital Library Project (Cheshire II) ha implementado TileBars (http://elib.cs.berkeley.edu/TileBars/help.html) con algunas variaciones para adecuarlo a documentos de gran extensión. Así, en lugar de emplear el citado algoritmo para partir los documentos en partes, ha optado por dividirlos en páginas. Si el documento no contiene ninguno de los términos de consulta en varias páginas consecutivas, esa parte no figura completa en cuadritos, sino que se sustituye por un cuadro que contiene un aspa.
Si aún así, el rectángulo que representa al documento es aún más largo de lo que se puede representar en pantalla, se reduce el ancho de los cuadrados, y como última opción, si aún así resulta grande, se incluyen barras de scroll o desplazamiento laterales para estirar el rectángulo.
Figura 23. TileBars. El catálogo de la biblioteca digital Cheshire II presenta los resultados mediante este sistema, http://elib.cs.berkeley.edu/TileBars/
Con las técnicas que se han mostrado en este artículo, la investigación pretende ofrecer soluciones al mayor problema de la representación de la información, que no es tanto técnico como cognitivo, es decir, mostrar al usuario del sistema un modelo de éste que sea capaz de comprender con el mínimo esfuerzo mental y asimilarlo para poder manejarlo sin problemas. Si el usuario no logra crear un modelo mental adecuado del sistema, esto es, una abstracción correcta de él, la representación que se le ofrece no habrá cumplido su objetivo. Por eso se hace necesario continuar desarrollando aplicaciones que mejoren esta comunicación del sistema con el usuario, en definitiva, la Interacción Persona-Ordenador.
Existe un gran campo de investigación en la aplicación de la visualización en sistemas de recuperación de información. De hecho, hay que decir que por el momento la mayoría de los sistemas de recuperación de información que incorporan técnicas de visualización son prototipos realizados en laboratorios de investigación. Por otro lado, la investigación en visualización de información todavía tiene mucho campo que estudiar y evaluar para obtener resultados satisfactorios que puedan competir con productos más tradicionales de recuperación de información.
Como se puede observar en los ejemplos mostrados, la mayoría de los sistemas que emplean técnicas de visualización para mostrar la información se han desarrollado para trabajar con bases de datos a texto completo, o al menos con un campo de resumen, lo que permite contar con una cantidad de términos suficiente para hacer un tratamiento automático del lenguaje y establecer categorías por similitud. En el caso de bases de datos referenciales, la información de contenido del documento sólo se encuentra en los campos de título (con los problemas de ambigüedad que conlleva el lenguaje natural) o en los normalizados para descripción (descriptores o materias y códigos de clasificación), lo que hace más complicado establecer criterios de similitud.
Chalmers, M.; Chitson, P. (1992). "BEAD: explorations in information visualization". En: Belkin, N.; Ingwersen, P.; Pejtersen, A. (eds.). Proceedings of the Association for Computing Machinery Special Interest Group on Information Retrieval. SIGIR '92. Copenhague, 1992. New York: ACM, 330-337, http://www.ACM.org/pubs/articles/proceedings/ir/133160/p330-chalmers/p330-chalmers.pdf
Cugini, J.; Laskowski, S.; Sebrechts, M. (2000). "Design of 3-D visualization of search results: evolution and evaluation". Proceedings of IST/SPIE's 12th Annual International Symposium: Electronic Imaging 2000: Visual Data Exploration and Analysis (SPIE 2000) , http://www.itl.nist.gov/iaui/vvrg/cugini/uicd/nirve-paper.html
Cugini, J.; Piatko, C.; Laskowski, S. (1996). " Interactive 3D visualization for document retrieval". Proceedings of the Workshop on New Paradigms in Information Visualization and Manipulation. ACM Conference on Information and Knowledge Management (CIKM '96) , http://zing.ncsl.nist.gov/~cugini/uicd/viz.html
Dürsteler, Juan Carlos. Infovis. Consultado: 27-ene-2005, http://www.infovis.net
Dürsteler, Juan Carlos (2000). Visualización de información. Barcelona: Gestión 2000. ISBN 84-8088-836-9.
Foltz, M. (1997, act. 2002). An information space design rationale. Consultado: 27-ene-2005, http://www.infoarch.ai.mit.edu/jair/jair-rationale.html
Hearst, M. (1999). "User interfaces and visualization". En: Baeza-Yates, Ricardo; Ribeiro-Neto, Berthier. Modern Information Retrieval. New York: Adison-Wesley, pp. 257-323.
Hearst, M. (1995). "TileBars: Visualization of term distribution information in full text information access". En: Katz, I. et al. Mosaic of Creativity: CHI '95: Proceedings of the Association for Computing Machinery Special Interest Group on Computer Human Interaction (ACM/SIGHCI). Conference on Human Factors in Computing Systems (Denver, May 1995). New York: ACM Press, 59-66, http://www.ACM.org/SIGCHI/chi95/Electronic/documnts/papers/mah_bdy.htm
Hearst, M.A.; Karadi, C. (1997). "Cat-a-Cone: An Interactive Interface for Specifying Searches and Viewing Retrieval Results using a Large Category Hierarchy". En: Belkin, N et al. (eds.). Proceedings of the 20th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR '97). New York: ACM, 236-245, http://www.ACM.org/pubs/contents/proceedings/ir/258525/ http://www.sims.berkekey.edu/~Hearst/papers/cac-sigir97/sigir97.html
Hemmje et al. (1994). "LyberWorld: A visualization user interface supporting fulltext retrieval". En: Croft, W.; Van Rijsbergen, C. (eds.). SIGIR '94: Proceedings of the Association for Computing Machinery Special Interest Group on Information Retrieval (ACM/SIGIR). 17th Annual International Conference on Research and Development in Information Retrieval (Dublin, Ireland, July 1994). London: Springer-Verlag, 249-259.
Information Visualization. Consultado: 27-ene-2005, http://www.palgrave-journals.com/ivs/
Korfhage, R. (1997). Information Retrieval Bibliography. VIRI systems bibliography organized according to the name or type of visualization system, http://www.pitt.edu/~Korfhage/VIRI_bib.htm
Kruskal, J. (1964a). "Nonmetric multidimensional scaling: a numerical method". Psychometrika , 29:2, 115-129.
Kruskal, J. (1964b). "Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis". Psychometrika , 29 :1, 1-27.
Lin, X. (1991). "A Self-Organizing Semantic Map for Information Retrieval", SIGIR'91 , 262-269.
Lin, X. (1992). "Visualization for the Document Space". En: Proceedings Visualization'92 , Boston: IEEE, 274-281.
Lin, X. (1997). "Map displays for Information Retrieval". Journal of the American Society for Information Science , 48, 40-54.
Mackinlay, J.; Robertson, G.; Card, S. (1991). "The Perspective Wall: detail and context smoothly integrated". En: P roceedings of ACM CHI'91 Conference on Human Factors in Computing Systems , New Orleans, Louisiana, April 28-May 2. ACM Press, 173-179.
Morse, E.; Lewis, M. (1997). "Why information visualizations sometimes fail". Proceedings of the IEEE International Conference on Systems Man and Cybernetics (Orlando, Florida, October 11-15) , http://www.itl.nist.gov/iaui/vvrg/emorse/papers/smc97.html
Olsen, K. A.; et al. (1993). "Visualization of a Document Collection: The VIBE System". Information Processing & Management , 29:1, 69-81.
Robertson, G.; Mackinlay, J.; Card, S. (1991). "Cone trees: animated 3d visualizations of hierarchical information". En: Proceedings of ACM SIGCHI'91 Conference on Human Factors in Computing Systems, (New Orleans, Louisiana, April 28-May 2). New York: ACM Press, 189-194.
Shneiderman, B. (1992). Designing the User Interface: Strategies for Effective Human-Computer Interaction. Reading (Ma): Addison-Wesley.
Mari Carmen Marcos forma parte del Grupo DigiDoc del Instituto Universitario de Lingüística Aplicada de la Universidad Pompeu Fabra y de la Sección Científica de Ciencias de la Documentación del Departamento de Ciencias Políticas y Sociales de la Universidad Pompeu Fabra. Este artículo presenta una parte de los resultados del proyecto HUM2004-03162/FILO del Plan Nacional I+D+I del Ministerio de Educación y Ciencia (España)
{kind=link}