
Autor: Antonio de la Rosa (Universidad de Granada)
Citación recomendada: Antonio de la Rosa. Introducción a XML para Documentalistas [en linea]. "Hipertext.net", núm. 1, 2003. <http://www.hipertext.net>
1. Nuevas posibilidades para bibliotecarios y documentalistas
2. Antecedentes del formato xml
3. Introducción a xml
4. Componentes y características de xml
4.1. Elementos
4.2. Atributos
4.3. Referencias de entidad
4.4. Comentarios
4.5. Instrucciones de proceso
4.6. Secciones cdata
4.7. DTD (document type declaration)
4.7.1. Declaración de elementos en una dtd
4.7.2. Declaración de atributos en una dtd
4.7.3. Declaración de entidad en una dtd
4.7.4. Validación de una dtd
5. Presentación y transformación de XML con XSLT (Extensible Stylesheet
6. Conclusión
7. Recursos consultados
8. Notas
Si uno se pregunta por el fenómeno más destacable en el campo de la Biblioteconomía y Documentación en los últimos 15 años, éste es sin duda la enorme superproducción de información. El problema es particularmente alarmante en el foro más popular de consulta e intercambio de información digital: Internet.
Ante esta situación, muchos profesionales de la documentación razonamos de la siguiente forma: hay demasiada información, luego la gente no puede encontrar la que necesita por sus propios medios, mientras eso sea así, tendremos trabajo.
Pero los papeles están cambiando en este nuevo entorno digital. El usuario es una persona cada vez más capacitada para encontrar información por si mismo, gracias al hecho de que está muy familiarizado [1] con el medio en que la busca. Es innegable que el porcentaje de usuarios que realiza sus búsquedas de información directamente en Internet sin necesidad de intermediarios está creciendo. También es un hecho que la producción de documentación en formato digital aumenta en comparación con la de información en otros formatos.
Paradójicamente son los conocimientos de carácter más "tradicional" de los bibliotecarios y documentalistas los que se requieren en el entorno digital actualmente. Nunca había habido tanta demanda de conocimientos sobre catalogación y clasificación, elaboración de índices, tesauros y taxonomías, orientación sobre normalización de descriptores o sobre los algoritmos más eficientes de recuperación de información.
El ingente volumen de información digital y la creciente cantidad de formatos y plataformas requiere urgentemente que la información se organize de forma inteligente y consistente. Los documentalistas y bibliotecarios sabemos catalogar e indizar; también hemos hecho interesantes aportaciones técnicas como el MARC21, Dublín Core [2] , el protocolo de recuperación de información Z39.50 y su especificación para aplicaciones bibliotecarias: Bath Profile. Todo esto indica que la gente de nuestra profesión tiene algo que decir cuando se trata de organizar e intercambiar información digital.
En este aspecto, uno de los campos de más actualidad en Internet es la elaboración y mantenimiento de taxonomías. La función de una taxonomía en el entorno digital es aumentar la eficiencia de la intranet corporativa o "sistema de gestión de conocimiento" de turno en aspectos tan familiares para los bibliotecarios y documentalistas como la relevancia y precisión en la recuperación de datos, reutilización y mantenimiento de los documentos, elaboración de interfaces temáticas etc.
El caso es que las taxonomies, funcionalmente, no están tan lejos de los tesauros [3] , sobre todo cuando se trata de las versiones digitales de ambos instrumentos. El caso es que si se necesitan lenguajes controlados de indización en Internet: ¿quien mejor para confeccionarlos que un profesional?
Pero ¿cuantos bibliotecarios o documentalistas son claramente conscientes de estas necesidades? y ¿cuántos conocen los medios técnicos que pueden convertir por ejemplo, nuestros conocimientos teóricos sobre indización en una solución específicamente adaptada a la web? Este artículo es una introducción básica a uno de esos medios: el formato XML (Extensible Markup Language).
Como se verá en los siguientes apartados, XML trata el contenido de un documento digital como una estructura arbórea de elementos [4]. Este enfoque viene de las técnicas empleadas por los primeros procesadores de texto. La evolución de este campo se puede resumir en las siguientes etapas:
A principios de los 60 se generaba en primer lugar el texto electrónico y después se le aplicaba el formato deseado. Por lo general la salida de este texto se producía de modo impreso. Estos textos tenían asociada, junto a la información propiamente dicha, la descripción deseada. Dicha descripción era convertida por el procesador de texto en una presentación. Algunas de las notaciones utilizadas en esta época siguen estando vigentes hoy en día como es el caso de RTF (Rich Text format).
Poco después apareció el marcado de formato que consistía en marcar directamente el texto mediante un conjunto de etiquetas o códigos.
Con la aparición de sistemas WYSIWYG (what you see is what you get), por un lado, se desarrollaron lenguajes de etiquetas más complejos, por otro, los procesadores de texto evolucionaron cualitativamente hasta llegar a los actuales: AmiPro, Pagemaker, Word, WordPerfect etc.
La proliferación de diversos formatos generó un problema: la información tenía diferentes maneras de representarse. Dentro de este contexto apareció, a finales de los 60 el GML ("General Markup Language"), una aportación de IBM que posteriormente se convertiría en SGML ("Standard Generalized Markup Language") el cual adquirió el estatus de norma ISO en 1986 (ISO 8879).
SGML permite especificar la estructura de un documento mediante una definición formal llamada DTD ("Document Type Definition") [5]. La DTD especifica qué "elementos" componen un documento como por ejemplo secciones, subsecciones, párrafos, encabezamientos, títulos etc.
A principios de los 70 apareció ARPANET, el precedente de Internet. Uno de los conceptos en los que se basaba era el de hipertexto. El hipertexto [6] se basa en la organización no secuencial de los documentos, lo que supone la adopción del criterio de asociación de conceptos [7] como principio organizador.
Los dos elementos clave de este sistema son el enlace y el nodo. Un nodo es en Internet un documento digital relacionado con otros por medio de enlaces. Una de las formalizaciones más populares de este modelo es la World Wide Web [8]. Los nodos o documentos digitales publicados en la web están codificados en HTML ("Hypertext Markup Language"). HTML, desarrollado a finales de los 80, no es ni más ni menos que una DTD SGML que especifica que "elementos" componen un documento digital publicado en la web.
El World Wide Web Consortium centralizó desde 1996 el desarrollo de HTML. Esa misma entidad ha sido la ha propuesto y desarrollado el formato XML, fundamentalmente por tres motivos:
Se buscaba una norma para intercambiar información estructurada entre dos puntos de la red con independencia de plataformas y aplicaciones. SGML era un candidato ideal, el unico problema era su complejidad y tamaño.
Se quería publicar documentos digitales en la World Wide Web a gran escala.
HTML sólo sirve para formalizar el formato de los documentos y no su contenido.
Para ello se seleccionó y adaptó un subconjunto de la norma SGML que es lo que ha dado lugar a la actual especificación XML
Lo interesante de esta evolución es constatar como en un momento determinado se produjo una separación entre estructuración de la presentación y estructuración del contenido. En estos momentos es la estructuración del contenido de la web lo que concentra la atención de usuarios y desarrolladores. De ahí el éxito del formato XML, XML es un medio de para estructurar el contenido de los documentos digitales.
Para trabajar con XML, por lo tanto, es necesario estructurar la información. Este es un proceso familiar para los bibliotecarios y documentalistas ya que todos los materiales con los que estamos acostumbrados a trabajar son susceptibles de ser divididos en componentes. Así, un libro tiene título, capítulos, índices... o un artículo resumen, apartados, subapartados, notas al pie, etc. Al mismo tiempo, cada una de estas partes tiene a su vez párrafos, frases, imágenes... XML denomina a todos estos componentes estructurales elementos.
Imaginemos que en una editorial se lleva un registro de los libros que se han vendido al cabo del año. Es un registro muy simple, al encargado sólo le interesa saber el código asignado a cada libro, el tema de que trata, la fecha de publicación, el título y el número de ejemplares vendidos durante el año. Aunque parezca mentira, sigue existiendo la opción de escribir todos estos datos en un papel. El registro tendría el siguiente aspecto:
Código:16-048
Categoría:Scripting
Fecha de publicación:1998-04-21
Título: Instant JavaScript
Ejemplares vendidos: 375298
Código: 16-105
Categoría: ASP
Fecha de publicación: 1998-05-10
Título: Instant Active Server Pages
Ejemplares vendidos: 297311
Código: 16-041
Categoría: HTML
Fecha de publicación: 1998-03-07
Título: Instant HTML
Ejemplares vendidos: 127853
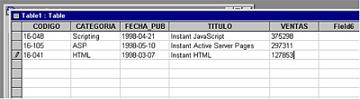
Otra opción sería digitalizar la información. Lo más fácil para ello sería mecanografiar la lista en un documento electrónico usando algún procesador de textos como Word o Word Perfect. Con este cambio ya se obtienen ciertas ventajas, como por ejemplo el hecho de que la información se pueda buscar, reutilizar, reeditar etc. El problema es que la lista de libros sigue siendo una lista y no se puede acceder o gestionar las unidades informativas inferiores, por ejemplo, un libro, de forma independiente. Para cambiar eso es posible introducir la información en una base de datos. Además de todas las ventajas generales del formato electrónico, una base de datos reduce la información a unidades informativas independientes. La lista de libros se representaría mediante la siguiente tabla en una base de datos relacional:
Ahora que tenemos la información en formato electrónico, podríamos publicarla en la web. Para ello habría que codificarla en formato HTML. Cuando introducimos una dirección en la ventana de direcciones de nuestro navegador estamos solicitando que se nos envíe una página o cadena de texto HTML. Como ya se comentó antes, HTML es una DTD de SGML ideada para dar formato a los documentos electrónicos. HTML es un lenguaje de etiquetas, es decir, está compuesto por una serie de etiquetas que describen el formato del contenido del documento. Por ejemplo en: <TITLE>Lista de libros</TITLE>, las etiquetas <TITLE></TITLE> indican que el contenido "Lista de libros" es un título y de esta forma, el navegador sabe que debe editar ese contenido en la barra superior a la izquierda. Una idea importante que se desprende de este ejemplo es que en HTML las etiquetas tienen un significado fijo, en otras palabras, HTML es un vocabulario. Codificada en HTML, la lista de libros podría tener el siguiente aspecto:
<HTML>
<HEAD>
<TITLE>Lista de libros</TITLE>
</HEAD>
<BODY BGCOLOR="#FFFFFF">
<H1>Lista de libros</H1>
<TABLE ALIGN="left" BORDER=1 WIDTH="100%"> <
TR ALIGN="left"VALIGN="middle">
<TH>CODIGO</TH>
<TH>CATEGORIA</TH>
<TH>FECHA_PUB</TH>
<TH>TITULO</TH>
<TH>VENTAS</TH>
</TR>
<TR ALIGN="left" VALIGN="middle">
<TD>16-048</TD>
<TD>Scripting</TD>
<TD>1998-04-21</TD>
<TD>Instant JavaScript</TD>
<TD>375298</TD>
</TR>
<TR ALIGN="left" VALIGN="middle">
<TD>16-105</TD>
<TD>ASP</TD>
<TD>1998-05-10</TD>
<TD>Instant Active Server Pages</TD>
<TD>297311</TD>
</TR>
;<TR ALIGN="left" VALIGN="middle">
<TD>16-041</TD>
<TD>HTML</TD>
<TD>1998-03-07</TD>
<TD>Instant HTML</TD>
<TD>127853</TD> </TR>
</TABLE></BODY>
</HTML>
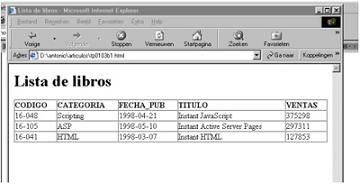
Este código, interpretado por un navegador produciría la siguiente presentación:
Ahora bien, con HTML lo único que conseguimos es relacionar el contenido con el tipo de presentación que queremos utilizar, por ejemplo: nuestra lista de libros es presentada como una tabla. Pero eso no afecta al contenido en si, que ha vuelto a dónde estabamos al principio. Aquí es donde entra en escena XML, XML no es un vocabulario como HTML, las etiquetas XML no significan nada para un navegador a menos que construyamos un navegador especial programado para reconocer esas etiquetas. No, XML es un lenguaje, un lenguaje que podemos utilizar para gestionar el contenido de un documento digital. La lista de libros en formato XML tendría el siguiente aspecto:
<?xml version="1.0" encoding="UTF-7" standalone="yes"?>
<LISTADELIBROS>
<LIBRO>
<CODIGO>16-048</CODIGO>
<CATEGORIA>Scripting</CATEGORIA>
<FECHA_PUB>1998-04-21</FECHA_PUB>
<TITULO>Instant JavaScript</TITULO>
<VENTAS>375298</VENTAS>
</LIBRO>
<LIBRO>
<CODIGO >16-105</CODIGO>
<CATEGORIA>ASP</CATEGORIA>
<FECHA_PUB>1998-05-10</FECHA_PUB>
<TITULO>Instant Active Server Pages</TITULO>
<VENTAS>297311</VENTAS>
</LIBRO>
<LIBRO>
<CODIGO>16-041</CODIGO>
<CATEGORIA>HTML</CATEGORIA>
<FECHA_PUB>1998-03-07</FECHA_PUB>
<TITULO>Instant HTML</TITULO>
<VENTAS>127853</VENTAS>
</LIBRO>
</LISTADELIBROS>
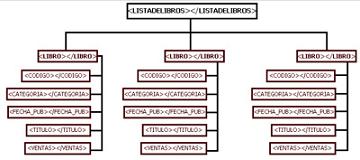
La representación gráfica de este código resulta en un árbol de etiquetas en el que se puede apreciar con mayor facilidad la estructura jerárquica del contenido:
Para resaltar todavía más la diferencia entre las etiquetas y el contenido al que se refieren, se puede añadir este al gráfico:
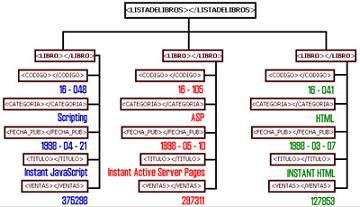
En ambos gráficos se puede apreciar que la información se representa de forma jerárquica. Los elementos de jerarquía inferior deben hallarse correctamente "incluídos" dentro de los de jerarquía superior. El elemento <LIBRO></LIBRO>, por ejemplo, debe incluirse dentro del elemento <LISTADELIBROS></LISTADELIBROS> y no al contrario. Una consecuencia de la estructura jerárquica es que los documentos XML sólo pueden tener un elemento raíz del que todos los demás descienden. El elemento raíz en el ejemplo es <LISTADELIBROS></LISTADELIBROS>.
Para que se produzca la formalización en XML se ha dado, por lo tanto, un proceso por medio del cual se ha hecho explicita la estructura de la información en forma de una jerarquía de elementos interrelacionados. El establecimiento de esta jerarquía y la identificación de esas interrelaciones aporta cierta "información" sobre la información original; por ello, a veces se dice que XML es un "metalenguaje".
Un documento XML comienza siempre con una instrucción de proceso. La presencia de esta instrucción indica explícitamente que el documento es XML y con qué versión de XML ha sido confeccionado [9]. El código XML utilizado como ejemplo comenzaba con la siguiente expresión:
<?xml version="1.0" encoding="UTF-7" standalone="yes"?>
Esto indica que el código tras la instrucción está sujeto a la sintaxis de la especificación XML, versión 1.0. Además se especifica el conjunto de caracteres que se van a utilizar en el documento, por ejemplo: US-ASCII, UTF-8, UCS-2, EUC-JP, Shift_JIS, Big5, ISO-8859-1 hasta ISO-8859-7. En general, en Europa se utiliza UTF-7 o ISO-8859-1.
XML como lenguaje, es la combinación de una serie de entidades: elementos, atributos, referencias de entidad, comentarios, instrucciones de proceso, secciones CDATA y DTDs mediante un conjunto de reglas sintácticas. De aquí en adelante se van a comentar brevemente esas entidades.
Los elementos son el recurso básico que utilizan los lenguajes de marcas como HTML, SGML o XML para identificar y manejar el contenido de los documentos. La función de los elementos en XML es definir la naturaleza del contenido al que etiquetan y localizar ese contenido en el contexto del documento. En las figuras de árboles del apartado anterior, los nodos de los árboles son elementos.
La representación práctica de un elemento son las etiquetas, identificadas por la presencia de los símbolos: < >. Todo elemento comienza con una etiqueta de inicio: <DOCUMENTO> y termina con una de cierre: </DOCUMENTO>. A diferencia de HTML, la etiqueta de cierre es obligatoria en XML [10]. Un elemento puede tener contenido o bien ser un elemento vacío. Por contenido se entiende contenido primario, como por ejemplo texto:
<LIBRO>Instant HTML</LIBRO>
U otros elementos jerárquicamente inferiores que, a su vez, pueden tener contenido o estar vacíos:
<LIBRO> <
CODIGO>16-041</CODIGO>
<CATEGORIA>HTML</CATEGORIA>
<FECHA_PUB>1998-03-07</FECHA_PUB>
<TITULO>Instant HTML</TITULO>
<VENTAS>127853</VENTAS>
</LIBRO>
Un elemento vacío es el que no presenta contenido primario ni contiene otros elementos:
<identificador tipo="DNI" valor="18935674-v"/>
Al no tener una etiqueta específica de "cierre" que delimite un contenido, se utiliza la forma <identificador/>. Esta es otra diferencia [11] con HTML dónde se permiten los elementos vacíos, sin etiquetas de cierre, como por ejemplo: <HR>, <BR> o <IMG>.
En el ejemplo [12] se utilizan los siguientes elementos: <LISTADELIBROS> </LISTADELIBROS> [13] , <LIBRO> </LIBRO>, <CODIGO> </CODIGO>, <CATEGORIA> </CATEGORIA>, <FECHA_PUB> </FECHA_PUB>, <TITULO> </TITULO> y <VENTAS> </VENTAS>. Aunque todos ellos son elementos, su nivel jerárquico en la estructura del documento es diferente, y por ello se da la circunstancia de que unos son subelementos de los otros, circunstancia que en el ejemplo aparece reflejada mediante la indentación.
Como hemos visto, la concepción básica que utiliza XML para organizar un documento es el modelo de árbol. Los elementos (el contenido) del documento constituyen una pequeña base de datos cuya estructura es arbórea y jerárquica en lugar de la tradicional estructura tabular de las bases de datos relacionales.
Los atributos siguen al nombre del elemento en las etiquetas de inicio. Su función es definir las propiedades de ese elemento. Podemos definir el elemento: <CAPITULO NUMERO="7">. En este caso tenemos: el elemento CAPITULO, el atributo NUMERO y el valor del atributo: "7". En el ejemplo anterior el elemento <identificador/> presentaba dos atributos: tipo y valor. El valor de los atributos debe especificarse entre comillas del tipo (') o ("). A veces un elemento con contenido puede formalizarse como un elemento vacío con atributos. Esto significa que la misma información se puede codificar de distintas formas en XML, una vez elegida una es muy aconsejable usarla consistentemente [14] :
<identificador tipo="DNI" valor="18935674-v"/>
<identificador tipo="DNI">18935674-v</identificador>
<identificador>
<tipo>DNI</tipo>
<valor>18935674-v</valor>
</identificador>
En XML cinco caracteres han sido reservados para usos especiales. Por ejemplo: "<" identifica el comienzo de una etiqueta de principio o de final. Si se quiere incluir esos caracteres en el contenido primario de un elemento debe haber una forma alternativa de representarlos. En XML se usan las entidades para este fin:

Los comentarios comienzan con "<!--" y terminan con "-->" [15]. Se puede emplazar comentarios en cualquier lugar del documento, excepto dentro de las propias etiquetas o dentro de otros comentarios. No se consideran parte del contenido textual de los documentos XML y son ignorados por los procesadores. Un ejemplo:
<!-- Esto es un comentario -->
Las instrucciones de proceso están pensadas para proporcionar información a las aplicaciones. Como los comentarios, no son parte del contenido textual de los documentos XML, pero a diferencia de ellos, los procesadores XML los tienen en cuenta y pasan la información que contienen a las aplicaciones designadas para procesar esa información. Los nombres de instrucciones de proceso que comiencen con "XML" se reservan para la normalización de XML, como la primera línea de nuestro ejemplo:
<?xml version="1.0" encoding="UTF-7" standalone="yes"?>
Además de las referencias de entidad existe otra construcción en XML que permite especificar datos, utilizando cualquier carácter, especial o no, sin que se interprete como código XML. Una sección CDATA indica al procesador que ignore el contenido de esa sección y lo trate como información ajena a XML. Esto es útil cuando, por ejemplo, se quiere incluir código fuente de algún lenguaje de programación en el documento XML. Este código puede contener caracteres que un parser XML reconocería como parte del marcado [16] , por ejemplo "<" o "&". Se pueden usar las secciones CDATA para prevenir esta confusión.
<ejemplo>
<![CDATA[
<script language="javascript">
alert("Este código no es XML")
</script>
]]>
</ejemplo>
4.7. DTD (document type declaration)
Una de las grandes virtudes de XML es que permite la creación de nuevas etiquetas. Sin embargo, un documento XML en el que las etiquetas se den en un orden completamente arbitrario carece de sentido para las aplicaciones. El ejemplo que se ha usado hasta el momento podría convertirse en algo así:
<?xml version="1.0" encoding="UTF-7" standalone="yes"?>
<LIBRO><CODIGO>16-048</CODIGO>16-105<?xml-stylesheet type="text/css"
href="listadelibros.css"?><LISTADELIBROS>
<!DOCTYPE LISTADELIBROS SYSTEM "listadelibros.dtd"> <CATEGORIA>Scripting</CATEGORIA><FECHA_PUB>1998-04-21</FECHA_PUB>
<TITULO>Instant JavaScript<VENTAS>375298</VENTAS></TITULO>
</LIBRO><LIBRO><CODIGO ><CATEGORIA>ASP</CATEGORIA></CODIGO> <FECHA_PUB>1998-05-10</FECHA_PUB>Instant Active Server Pages
<TITULO></TITULO><VENTAS>297311</VENTAS>
</LIBRO><LIBRO>
<FECHA_PUB>1998-03-07</FECHA_PUB><TITULO>Instant HTML</TITULO> <VENTAS>127853<CODIGO>16-041</CODIGO><CATEGORIA>HTML</CATEGORIA><
/VENTAS></LIBRO>
</LISTADELIBROS>
Un documento así no tiene ningún sentido. Sin embargo, desde un punto de vista estrictamente sintáctico [17] , es un documento correcto. Si se desea que el documento tenga sentido debe haber ciertas restricciones en la secuencia y forma de anidar los elementos. Esas restricciones pueden expresarse mediante una "declaración". La Document Type Declaration es uno de los tipos posibles de declaración en XML.
En general, las declaraciones permiten a un documento comunicar meta-información sobre la estructura de su contenido a la aplicación que lo analiza. Esta meta-información incluye: la secuencia de elementos en el documento y la forma en que se anidan, los tipos de atributos, sus valores y sus valores por defecto, los nombres de archivos externos que se hallen referenciados en el documento, los formatos sobre datos no XML que puedan aparecer en el documento y las entidades presentes.
Además, el procesador que analiza el documento XML debe ser capaz de determinar si éste está bien formado, es decir, es correcto según la sintaxis XML y/o es válido, es decir, además de estar bien formado atiende a las restricciones definidas en su declaración [18].
En una DTD se pueden declarar elementos, atributos, entidades y notaciones.
4.7.1. Declaración de elementos en una dtd
Se trata de identificar los nombres de los elementos incluídos en un documento y la naturaleza de su contenido. Una declaración de elemento presenta la siguiente sintaxis:
<!ELEMENT "nombre del elemento" "categoría"> o <
!ELEMENT "nombre del elemento" ("contenido del elemento")>
Los elementos vacíos se declaran con la categoría EMPTY:
<!ELEMENT "nombre del elemento" EMPTY>
por ejemplo, en la DTD se definiría:
<!ELEMENT identificador EMPTY>
lo que en el código XML aparecería como:
<identificador/>
Los elementos que contienen exclusivamente texto y no otros elementos se declaran del siguiente modo:
<!ELEMENT VENTAS (#PCDATA)>
lo que en XML aparece como:
<VENTAS>127853</VENTAS>
Si en la categoría aparece el descriptor ANY, el elemento podrá contener cualquier tipo de contenido: otros elementos, texto, imágenes etc.
<!ELEMENT nota ANY>
Los elementos que contienen subelementos se definen con el nombre de esos subelementos entre paréntesis:
<!ELEMENT LIBRO (CODIGO, CATEGORIA, FECHA_PUB, TITULO, VENTAS)>
Cuando los subelementos se declaran en una secuencia separada por comas cómo en el ejemplo, deberán aparecer en la misma secuencia en el documento XML. En una declaración completa, los subelementos [19] deben declararse también por separado.
<!ELEMENT LIBRO (CODIGO, CATEGORIA, FECHA_PUB, TITULO, VENTAS)>
< !ELEMENT CODIGO (#PCDATA)>
< !ELEMENT CATEGORIA (#PCDATA)>
< !ELEMENT FECHA_PUB (#PCDATA)>
< !ELEMENT TITULO(#PCDATA)>
< !ELEMENT VENTAS (#PCDATA)>
Si se quiere declarar sólo una ocurrencia de un elemento:
<!ELEMENT LIBRO (CODIGO)>
El ejemplo anterior declara que el elemento "CODIGO" sólo puede ocurrir una vez dentro del elemento "LIBRO".
Si se quiere declarar "como mínimo" una ocurrencia del elemento:
<!ELEMENT LIBRO (CODIGO+)>
El signo de adición significa que el elemento "CODIGO" puede ocurrir más de una vez dentro del elemento "LIBRO", pero tiene que ocurrir como mínimo una vez.
Si se quieren declarar cero o más ocurrencias del elemento:
<!ELEMENT LIBRO (CODIGO*)>
El asterísco significa que el elemento "CODIGO" puede ocurrir cero o más veces dentro del elemento "LIBRO".
Si se quieren declarar cero o una ocurrencias del elemento:
<!ELEMENT LIBRO (CODIGO?)> El signo de interrogación significa que el elemento "CODIGO" puede ocurrir cero o una veces dentro del elemento "LIBRO".
Si se quieren declarar elementos opcionales:
<!ELEMENT LIBRO (CODIGO, (CATEGORIA|CDU)>
El ejemplo sobre estas líneas indica que el elemento "LIBRO" debe contener un elemento "CODIGO" y uno de los otros dos elementos: "CATEGORIA" o "CDU".
Si se quiere declarar un elemento de contenido mixto, es decir, que incluya texto junto a otros subelementos:
<!ELEMENT LIBRO (#PCDATA|CATEGORIA)>
El ejemplo indica que el elemento "LIBRO" puede contener texto o un elemento "CATEGORIA".
Una DTD simple de nuestro documento XML podría ser:
<!ELEMENT LIBRO (CODIGO, CATEGORIA*, FECHA_PUB?, TITULO, VENTAS?)>
<!ELEMENT CATEGORIA (#PCDATA)>
<!ELEMENT CODIGO (#PCDATA)>
<!ELEMENT FECHA_PUB (#PCDATA)>
<!ELEMENT LISTADELIBROS (LIBRO+)>
<!ELEMENT TITULO (#PCDATA)>
<!ELEMENT VENTAS (#PCDATA)>
Para asociar esta DTD al documento XML existen dos opciones: la primera es incluirla directamente en el código XML:
<?xml version="1.0" encoding="UTF-7" standalone="yes"?> <!DOCTYPE LISTADELIBROS[
<!ELEMENT LIBRO (CODIGO, CATEGORIA*, FECHA_PUB?, TITULO, VENTAS?)>
<!ELEMENT CATEGORIA (#PCDATA)>
<!ELEMENT CODIGO (#PCDATA)>
<!ELEMENT FECHA_PUB (#PCDATA)>
<!ELEMENT LISTADELIBROS (LIBRO+)>
<!ELEMENT TITULO (#PCDATA)>
<!ELEMENT VENTAS (#PCDATA)>
]>
<LISTADELIBROS>
<LIBRO>
<CODIGO>16-048</CODIGO>
<CATEGORIA>Scripting</CATEGORIA>
<FECHA_PUB>1998-04-21</FECHA_PUB> <TITULO>Instant JavaScript</TITULO>
<VENTAS>375298</VENTAS> </LIBRO>
<LIBRO> <CODIGO >16-105</CODIGO>
<CATEGORIA>ASP</CATEGORIA>
<FECHA_PUB>1998-05-10</FECHA_PUB>
<TITULO>Instant Active Server Pages</TITULO>
<VENTAS>297311</VENTAS> </LIBRO>
<LIBRO> <CODIGO>16-041</CODIGO>
<CATEGORIA>HTML</CATEGORIA>
<FECHA_PUB>1998-03-07</FECHA_PUB>
<TITULO>Instant HTML</TITULO> <VENTAS>127853</VENTAS> </LIBRO>
</LISTADELIBROS>
O guardarla en un archivo al que asignaremos la extensión ".dtd" y referir a ese archivo desde el documento XML usando la siguiente sintaxis:
<!DOCTYPE LISTADELIBROS SYSTEM "C:/articulos/xml/listadelibros.dtd">
4.7.2. Declaración de atributos en una dtd
Se trata de identificar los nombres de los atributos usados en los elementos de un documento XML y la naturaleza de su contenido. Una declaración de atributo presenta la siguiente sintaxis:
<!ATTLIST "nombre elemento" "nombre atributo" "tipo atributo" "valor por defecto">
Por ejemplo:
<!ATTLIST identificador tipo CDATA "DNI">
lo que en el código XML aparecería como:
<identificador tipo="DNI"/>
El tipo de atributo puede tener los siguientes valores:
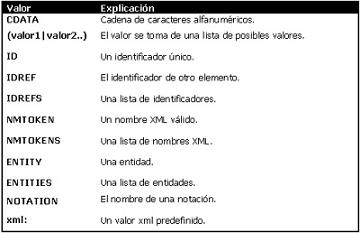
El valor por defecto puede tener los siguientes valores:

Las tablas sobre estas líneas pueden parecer algo crípticas, a continuación se ofrecen algunos ejemplos:
<!ELEMENT RECTANGULO EMPTY>
<!ATTLIST RECTANGULO anchuracm CDATA "0">
El elemento rectángulo es definido cómo un elemento vacío con un atributo "anchuracm" del tipo CDATA. Si en el código XML no se especifica otro valor, el valor por defecto del atributo será 0. En cualquiera de los dos casos, el atributo siempre tendrá un valor.
<!ATTLIST CONTACTO numero_fax CDATA #IMPLIED>
Con la opción #IMPLIED, no es necesario que el atributo tenga un valor.
<!ATTLIST LIBRO codigo CDATA #REQUIRED>
Con la opción #REQUIRED, no es necesario que el atributo tenga un valor por defecto, pero el atributo debe tener un valor, por lo tanto, el autor del documento XML debe asignarle uno.
<!ATTLIST PROVEEDOR nombre CDATA #FIXED "IBM">
Con la opción #FIXED, el autor no puede cambiar el valor por defecto que se haya definido en la declaración.
<!ATTLIST identificador tipo (DNI|Passaporte) "DNI">
Con la opción de ennumeración de valores, el valor del atributo puede elegirse en una lista de posibles valores.
4.7.3. Declaración de entidad en una dtd
Las declaraciones de entidad permiten asociar un nombre con algún otro fragmento del documento: datos regulares, partes de DTD's o archivos externos.
Las dos clases de entidades básicas son:
ENTIDADES INTERNAS: permiten definir abreviaturas para el texto que aparece a menudo o el que se espera que cambie. <!ENTITY nombre "Antonio de la Rosa"> <!ENTITY copyright "Copyright 2002"> a lo que correspondería la siguiente referencia en el código XML: <AUTOR>&nombre;©right;</AUTOR>
ENTIDADES EXTERNAS: permiten a un documento XML referirse a un archivo externo. Estos archivos pueden contener texto o datos binarios. Si es texto, el contenido del archivo se insertará en lugar de la referencia y será procesado como parte del documento. Si son datos binarios no serán procesados sino pasados a otra aplicación capaz de procesarlos. <!ENTITY nombres "http://www.wisdom.nl/blabla/autores.xml"> a lo que correspondería la siguiente referencia en el código XML: <AUTORES>&nombres;</AUTORES>
Si nuestro documento XML está asociado a una DTD, será necesario confirmar de alguna manera que el código XML se corresponde con lo que está definido en la DTD. Este proceso se conoce como validación de un documento XML y ocurre normalmente de manera automática gracias a un programa llamado parser. Un parser analiza la DTD y después el código del documento XML, si ese código cumple los requisitos explícitos en la DTD se dice que es un documento XML válido. En la actualidad, lo normal es que los parsers esten integrados en "Entornos de desarrollo" XML como es el caso de XMLSpy [20]. En cualquier caso, si alguien esta interesado en software relacionado con XML siempre puede visitar: http://www.xmlsoftware.com.
Language: Transformations) Hasta ahora se ha hablado exclusivamente de XML, pero no de lo que se puede hacer con XML. Las posibilidades son realmente ilimitadas, pero en este apartado vamos a concentrarnos en una, la transformación de un documento XML mediante una hoja de estilo XSLT.
La función de XSLT se describe a menudo como: "transformar XML para su presentación". Lo que esto realmente significa es que no hay una forma normalizada de presentar elementos XML, ya que, a diferencia de HTML, los elementos XML no poseen ningún significado intrínseco.
Lo que hace XSLT es permitir que el autor o el receptor del documento XML puedan especificar como se debe presentar el contenido del documento. Generalmente los elementos XML se transformarán en elementos HTML; en otras palabras, se especificará código HTML para cada elemento XML y este código será el encargado de producir la presentación deseada. Si los elementos creados son válidos en HTML y XML, el navegador los presentará en pantalla.
Algo a destacar es la posibilidad de usar XSLT para crear nuevos elementos o eliminar elementos existentes en el documento fuente. XSLT presenta la posibilidad de copiar elementos del documento fuente en el nuevo documento, usar estructuras de decisión para presentar sólo ciertos elementos preseleccionados, crear nuevos elementos u ordenar el contenido del documento fuente de forma diferente a la original antes de presentarlo.
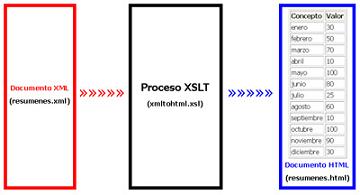
Para ver todo esto en la práctica pongamos otro ejemplo de documento XML, el documento resumenes.xml: <?xml version="1.0" encoding="ISO-8859-1" ?> <?xml-stylesheet type="text/xsl" href="xmltohtml.xsl"?>
<resultados intervalo="10" valormaximo="100">
<item nombre="enero">30</item>
<item nombre="febrero">50</item>
<item nombre="marzo">70</item>
<item nombre="abril">10</item>
<item nombre="mayo">100</item>
<item nombre="junio">80</item>
<item nombre="julio">25</item>
<item nombre="agosto">60</item>
<item nombre="septiembre">10</item>
<item nombre="octubre">100</item>
<item nombre="noviembre">90</item>
<item nombre="diciembre">30</item>
</resultados>
La información empleada en este ejemplo es completamente arbitraria. Los valores de los elementos podrían referirse al número de altas mensuales en una biblioteca pública o al porcentaje de incremento de negocio de un banco. La diferencia fundamental con el ejemplo que describía la lista de libros es que este documento está asociado a la hoja de estilo xmltohtml.xsl mediante la referencia:
<?xml-stylesheet type="text/xsl" href="xmltohtml.xsl"?>
Esto significa que cuando el navegador IExplorer [21] lea el documento XML sabrá que debe ejecutar en él las transformaciones indicadas en la hoja de estilo xmltohtml.xsl. Esas transformaciones pueden dar ligar a diferentes formatos de salida:
XML con la misma estructura y diferentes datos.
XML con una estructura diferente.
HTML para publicar la información en la web.
PDF para conseguir una presentación agradable y mejores resultados a la hora de imprimir.
WML (Wireless Markup Language) para que sea posible consultar la información desde dispositivos de acceso no convencionales como teléfonos móviles y organizadores electrónicos.
RTF (Rich Text Format) como formato común interpretable por una amplia gama de programas, como la familia Office.
SVG (Scalable Vector Graphics) vocabulario XML para presentaciones gráficas.
Para llevar a cabo esas transformaciones se emplean hojas de estilo [22] escritas en el lenguaje XSLT o Extensible Style Language: Transformations. La recomendación XSLT fue desarrollada por el XSL Working Group y ratificada por el World Wide Web Consortium [23] , el mismo organismo que creo y difundió la norma XML. Como sucedía con las DTD's un parser XSLT analizará el documento XML, lo dividirá en componentes básicos y sobre estos ejecutará las instrucciones especificadas en la hoja de estilo XSLT asociada a él.
Las tres grandes ventajas que se pueden deducir inmediatamente de este sistema de transformaciones mediante hojas de estilo son:
Es posible reutilizar la información original tantas veces como sea preciso. Cuando se quiera obtener un resultado diferente sólo será necesario asociarla a una nueva hoja de estilo y no modificar el documento fuente.
La presentación y el contenido de un documento están separados [24].
Mediante la asociación de diferentes hojas de estilo al documento fuente se podrán obtener distintos formatos de salida.
La transformación XSLT más común en la web es la que convierte contenido XML en formato HTML para que pueda ser leída de forma estándar por un navegador web.
A continuación se va a elaborar una hoja de estilo XSLT para convertir resumenes.xml en el siguiente documento HTML, resumenes.html:
<html>
<head>
<title>Transformar XML en HTML</title>
</head>
<body>
<table border="1" cellpadding="2"cellspacing="3">
<tr bgcolor="#F5F4EB">
<td><b>Concepto</b></td>
<td><b>Valor</b></td> </tr>
<tr><td>enero</td><td>30</td></tr>
<tr><td>febrero</td><td>50</td></tr>
<tr><td>marzo</td><td>70</td></tr>
<tr><td>abril</td><td>10</td></tr>
<tr><td>mayo</td><td>100</td></tr>
<tr><td>junio</td><td>80</td></tr>
<tr><td>julio</td><td>25</td></tr>
<tr><td>agosto</td><td>60</td></tr>
<tr><td>septiembre</td><td>10</td></tr>
<tr><td>octubre</td><td>100</td></tr>
<tr><td>noviembre</td><td>90</td></tr>
<tr><td>diciembre</td><td>30</td></tr>
</table>
</body>
</html>
Cuando este documento es leído por el navegador Internet Explorer se obtiene la siguiente tabla:

Se puede apreciar a primera vista que la información es la misma en el documento original XML y en el nuevo documento HTML. En ambos se registra, por ejemplo, un valor de 90 asignado al mes de noviembre.
Esto significa que lo que ha cambiado en este caso no son los datos sino los elementos que contienen esos datos.
El elemento XML: <item nombre="noviembre">90</item>, concretamente, se ha convertido en el elemento HTML: <tr><td>enero</td><td>30</td></tr>. ¿Cómo? Mediante la asociación de la siguiente hoja de estilo XSLT (llamémosla xmltohtml.xsl) con el documento resumenes.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/...">
<xsl:output indent="yes"/>
<xsl:template match="resultados">
<html>
<head>
<title>Transformar XML en HTML</title>
</head>
<body>
<table border="1" cellpadding="2" cellspacing="3">
<tr bgcolor="#F5F4EB">
<td><b>Concepto</b></td>
<td><b>Valor</b></td>
</tr> <xsl:apply-templates select="item"/>
</table>
</body>
</html>
</xsl:template> <xsl:template match="item">
<tr>
<td>
<xsl:value-of select="@nombre"/>
</td>
<td>
<xsl:value-of select="."/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
La extraña indentación de la hoja de estilo no es casual. Si observamos el código atentamente vemos que coexisten elementos de tres clases diferentes que se estructuran según tres jerarquías distintas.
Esos elementos pueden agruparse (este es el hecho que se pretende destacar mediante la indentación) en tres bloques interrelacionados y al mismo tiempo, hasta cierto punto independientes unos de los otros.
Si se copia la hoja de estilo asignando un color diferente a cada uno de esos bloques, quizás los grupos de elementos y sus respectivas jerarquías se hagan más visibles:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/...">
<xsl:output indent="yes"/>
<xsl:template match="resultados">
<html>
<head>
<title>Transformar XML en HTML</title>
</head>
<body>
<table border="1" cellpadding="2" cellspacing="3"> lt;tr bgcolor="#F5F4EB"> <td><b>Concepto</b></td> <td><b>Valor</b></td> </tr> > <xsl:apply-templates select="item"/> </table> </body> </html> > </xsl:template> <xsl:template match="item"> <tr> <td> <xsl:value-of select="@nombre"/> </td> <td> <xsl:value-of select="."/> </td> </tr> </xsl:template> </xsl:stylesheet>
El primer grupo, color azul oscuro es, como ya hemos visto en apartados anteriores, una instrucción de proceso XML:
<?xml version="1.0" encoding="ISO-8859-1"?>
Esta instrucción es idéntica a la que aparece en la primera línea del documento resumenes.xml. Indica que el documento en cuestión se halla codificado en formato XML.
En el caso de resumenes.xml esto es obvio, pero la presencia de esa instrucción de proceso en la hoja de estilo requiere una explicación.
La explicación es que el lenguaje de transformación XSLT es un "vocabulario" XML, porque los elementos XSLT tienen un significado propio pero siguen respetando la sintaxis indicada en la norma XML.
Un documento XSLT, por lo tanto, sigue siendo un documento XML.
El segundo grupo , coloreado en rojo oscuro, está compuesto por los elementos XSLT propiamente dichos. El elemento de máxima jerarquía dentro de ese grupo, en el que todos los demás están anidados, es el elemento hoja de estilo o <xsl:stylesheet>:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/...">
En esta línea se indica que este documento XML en particular es una hoja de estilo escrita en XSLT. Al mismo tiempo, se proporciona un mecanismo de identificación de los elementos XSLT que se van a usar en la hoja de estilo.
Este mecanismo recibe el nombre de "XML NameSpace" o abreviado, como aparece en el código: "xmlns". La función de un NameSpace es especificar el ámbito de aplicación de los elementos. En esta hoja de estilo, solamente los elementos precedidos por el NameSpace "xsl" deben ser interpretados como "instrucciones" XSLT.
<xsl:output indent="yes"/>
<xsl:template match="resultados">
<xsl:apply-templates select="item"/>
<xsl:template match="item">
<xsl:value-of select="@nombre"/>
<xsl:value-of select="."/>
El objetivo de este artículo es introducir el formato XML y no explicar en profundidad el lenguaje XSLT o la semántica de estas instrucciones. Basta con saber que el principio básico es la selección de elementos o grupos de elementos (junto a sus atributos y / o valores) del documento original. Sobre esa selección es sobre la que se van a operar las transformaciones. Recordemos el documento original resumenes.xml:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<resultados intervalo="10" valormaximo="100">><item nombre="enero">30</item>
<item nombre="febrero">50</item>
<item nombre="marzo">70</item>
<item nombre="abril">10</item>
<item nombre="mayo">100</item>
<item nombre="junio">80</item>
<item nombre="julio">25</item>
<item nombre="agosto">60</item>
<item nombre="septiembre">10</item>
<item nombre="octubre">100</item>
<item nombre="noviembre">90</item>
<item nombre="diciembre">30</item>
</resultados>
De la hoja de estilo xmltohtml.xsl tomemos solamente los elementos XSLT y prestemos atención a su jerarquía, reflejada en la forma en que se anidan unos dentro de otros y gráficamente mediante la indentación y el color:
<xsl:stylesheet xmlns:xsl= "http://www.w3.org/...">
<xsl:output indent="yes"/>
<xsl:template match="resultados">
<xsl:apply-templates select="item"/>
</xsl:template>
<xsl:template match="item">
<xsl:value-of select="@nombre"/>
<xsl:value-of select="."/>
</xsl:template>
</xsl:stylesheet>
El elemento raíz <xsl:stylesheet> que contiene todos los demás es simplemente, como ya se ha dicho, la hoja de estilo.
Son los elementos <xsl:template> los que tienen importancia a la hora de comprender el funcionamiento de XSLT. Estos elementos son los que sirven para seleccionar ciertas "partes" del documento original.
En xmltohtml.xsl hay dos de esos elementos, el primero: <xsl:template match="resultados">, selecciona el contenido del elemento raíz XML <resultados> y el segundo: <xsl:template match="item">, el contenido de cada uno de los elementos XML <item>.
Centrémonos en este último elemento <xsl:template>. Dentro de él se dan otros dos elementos XSLT. El primero: <xsl:value-of select="@nombre"/>, selecciona el valor del atributo nombre dentro del primer elemento <item>; es decir: enero. El segundo: <xsl:value-of select="."/>, simplemente selecciona el valor del mismo elemento <item>; es decir: 30.
Esta información se obtiene del primer elemento <item>, pero, ¿qué es lo que permite seleccionar estos datos para todos y cada uno de los elementos <item>? en otras palabras ¿cómo se aplica recursivamente el template <xsl:template match="item"> a todos los elementos <item> del documento resumenes.xml? Mediante el primer template: <xsl:template match="resultados"> que se empareja con el elemento raíz del documento fuente XML: <resultados>, el cual contiene todos los elementos <item>. El subelemento <xsl:apply-templates select="item"/>. aplica a cada elemento <item> dentro del elemento <resultados> las instrucciones del segundo template explicado en el párrafo anterior y diseñado para seleccionar la información que necesitamos.
El tercer grupo, coloreado en verde, son simples elementos HTML que envuelven los datos obtenidos mediante las "instrucciones" XSLT. De esta forma dichos datos pueden ser presentados por cualquier navegador.
<html>
<head>
<title>Transformar XML en HTML</title>
</head>
<body>
<table border="1" cellpadding="2" cellspacing="3">
<tr bgcolor="#F5F4EB">
<td><b>Concepto</b></td>
<td><b>Valor</b></td>
</tr>
</table>
</body>
</html>
Unos párrafos antes se comentaba que el template <xsl:template match="item">, obtenía para un elemento <item> el valor de este elemento más el de su atributo nombre. Las etiquetas HTML que aparecen dentro de ese template servirán para tabular esa información:
<xsl:template match="item">
<tr>
<td>
<xsl:value-of select="@nombre"/>
</td>
<td>
<xsl:value-of select="."/>
</td>
</tr>
</xsl:template>
El proceso de transformación que se ha explicado se podría ejemplificar en el siguiente esquema:
En estas páginas se ha presentado a grandes rasgos el formato XML. Esta presentación no difiere en gran medida de los cientos que se pueden encontrar en la web, en libros o artículos. La aspiración de cualquiera de ellas es "presentar" de forma intelligible algo que ya existe: la especificación XML está en la web y es de acceso público.
Si hay alguna diferencia esta es la audiencia a la que esta presentación esta destinada: bibliotecarios y documentalistas. XML y todas las especificaciones asociadas a él son un medio para plantear soluciones a problemas concretos. Pero para plantear soluciones hay que aislar los problemas y analizarlos en profundidad. Muchos de los problemas de la web, pueden ser analizados desde el ángulo de la gestión de información, esa es nuestra tarea en el entorno digital y los conocimientos que tenemos para desempeñar esa tarea siguen siendo válidos.
Todas las posibilidades que ofrecen las especificaciones XML pueden ser aplicadas a cualquier sistema de información, cubriendo un gran porcentaje de las necesidades de profesionales y usuarios. Sólo hay que hacer lo que sabemos hacer utilizando nuevos instrumentos.
Especificación oficial HTML v4.0 (http://www.w3.org/TR/REC-html40)
Especificación oficial XML v1.0 (http://www.w3.org/TR/REC-xml)
Información oficial de XSL (XSLT/XPath) (http://www.w3.org/Style/XSL/)
MSDN Online XML Developers Center (http://msdn.microsoft.com/xml/)
The World Wide Web Consortium (http://www.w3c.org/)
XML.COM (http://www.xml.com/)
The XML Industry Portal (http://www.xml.org/)
XML Software Guide (http://wdvl.internet.com/Software/XML/)
[1] A veces, de hecho, el usuario está más familiarizado que los propios profesionales. [volver]
[2] Una de las normas de metadatos más respetadas. [volver]
[3] Para que nadie pueda acusarme de ignorancia o descuido adjunto las definiciones de taxonomía y tesauro: Taxonomía es la ciencia de la clasificación de un ámbito del conocimiento según un sistema predeterminado. Su función es proporcionar un marco conceptual para la discusión, el análisis o la recuperación de información. En teoría, el desarrollo de una taxonomía incluye la separación de los descriptores seleccionados en grupos y subgrupos no-ambigüos y mutuamente excluyentes. En el entorno digital, una taxonomia se puede aplicar por ejemplo en el diseño de un sitio web para describir las categories y subcategorías de tópicos de que consta la información que se va a publicar. Según la International Standard Organization un tesauro es el vocabulario de un lenguaje controlado de indización organizado formalmente de manera que las relaciones apriorísticas entre conceptos resulten explícitas. [volver]
[4] Entendiéndose por elemento una unidad informativa que puede englobar a otros elementos de jerarquía inferior y a su vez hallarse englobada en otros de jerarquía superior. [volver]
[5] Que se tratará más adelante. [volver]
[6] Entonces hipertexto, en la actualidad hipermedia sería más adecuado. [volver]
[7] O si se quiere, asociación temática. [volver]
[8] Que es básicamente el entorno al que se refiere este artículo,más que Internet en general. [volver]
[9] Hasta el momento la única versión disponible es 1.0. No hay nuevas versiones previstas a corto plazo. [volver]
[10] Esta, por ejemplo, es una de las reglas sintácticas a las que nos referíamos en un párrafo anterior. [volver]
[11] De nuevo una regla sintáctica. [volver]
[12] Tanto en el código XML cómo en su representación gráfica. [volver]
[13] Éste es un elemento especial llamado Elemento Raíz, es el elemento de jerarquía superior. La regla sintáctica que se aplica a este elemento es que él incluye al resto de elementos y no puede ser incluído por ninguno. [volver]
[14] También debe tenerse en cuenta que XML establece diferencias con respecto al tipo de letra, es decir, el elemento , es distinto de o [volver]
[15] El mismo formato que en HTML. [volver]
[16] Por ejemplo, si se quiere incluir código HTML en un documento XML. [volver]
[17] Como expresión EBNF Extended Backus-Naur formalización sintáctica en la que se basa XML. [volver]
[18] Sea DTD u otro tipo de declaración. [volver]
[19] Hay que tener en cuenta que los subelementos pueden tener, a su vez, subelementos, lo que significa que estos, deben también ser declarados. [volver]
[20] http://www.xmlspy.com [volver]
[21] IExplorer incluye un parser XSLT desde su versión 4. [volver]
[22] También se podrían llamar hojas de formato. [volver]
[23] http://www.w3c.org [volver]
[24] Al contrario de lo que ocurría en HTML. [volver]
